Splitgraph has been acquired by EDB! Read the blog post.
PostgreSQL FDW aggregation pushdown part II: Snowflake speedup
We demonstrate a concrete application of aggregation pushdown mechanism in the form of our Snowflake FDW. Actual performance benefits are quantified for a selection of real-life examples.
Introduction
Recently we talked about new capabilities which we have added to the Multicorn FDW framework, namely pushdown of aggregation and grouping queries to the remote data source. We've discussed the clear performance benefits of such a mechanism, for the most part significantly faster query execution times, and also gave a brief overview of the FDW fundamentals in PostgreSQL. Lastly, we demonstrated a working toy model utilizing these features: an FDW for querying Pandas dataframes via SQL.
In this blog post we will show an actual implementation building on that work, one centering on the Snowflake FDW. We start off by giving some insights on how this FDW works. Subsequently, we measure the resulting query speedup due to aggregation pushdown in some real circumstances. Finally, we revisit the subject of data filtering and qualifier pushdown in the context of aggregations.
SQLAlchemy
To facilitate querying Snowflake tables through Splitgraph we rely on SqlAlchemyFdw, one of many Multicorn-based FDWs that exist. Under the hood it employs SQLAlchemy ORM to talk with any remote data source with a supported dialect, one of which is Snowflake.
Recall that in order to utilize Multicorn's aggregation pushdown capabilities, the corresponding Python FDW implementation must first declare which aggregation functions are supported, in order for the aggregation pushdown plan to be chosen by Postgres in the first place.
Additionally, it must accept and act on two new keyword arguments in the execute method: aggs and group_clauses.
The former represents a mapping between each aggregation target and its constituent elements (i.e. column and function name),
while the latter is simply a list of columns referenced in the GROUP BY clauses.
Prototype
Let us prototype how (re-)constructing an aggregation query would look like in this case:
from sqlalchemy.schema import Table, Column, MetaData
from sqlalchemy.types import Integer, String
from sqlalchemy.sql import select, func
_PG_AGG_FUNC_MAPPING = {
"avg": func.avg,
"min": func.min,
"max": func.max,
"sum": func.sum,
"count": func.count,
"count.*": func.count
}
def aggregation_query(table, aggs=None, group_clauses=None):
target_list = []
if group_clauses is not None:
target_list = [table.c[col] for col in group_clauses]
if aggs is not None:
for agg_name, agg_props in aggs.items():
agg_func = _PG_AGG_FUNC_MAPPING[agg_props["function"]]
if agg_props["column"] == "*":
agg_target = agg_func()
else:
agg_target = agg_func(table.c[agg_props["column"]])
target_list.append(agg_target.label(agg_name))
statement = select(*target_list).select_from(table)
if group_clauses is None:
return statement
return statement.group_by(*[table.c[col] for col in group_clauses])
Note that targets passed to the select method correspond to plain columns if originating from group_clauses, or
functions acting on a column for each aggregation target. _PG_AGG_FUNC_MAPPING defines a mapping of PostgreSQL
functions to their SQLAlchemy counterparts.
The special case of count(*) is also supported; the corresponding column value is * and refers to all columns.
In such case we don't supply an argument to the underlying count function. It is worth pointing out that there is
a subtle difference between count(*) and count(some_column)—the latter doesn't count NULL-valued rows, while
the former takes them into account. Therefore we can't "cheat" and simplify our implementation by using the same remote
expression for both.
Testing this prototype out with a simple input:
In [1]: table = Table("test", MetaData(), Column("number", Integer), Column("parity", String(4)))
In [2]: aggs = {
...: "count.*": {
...: "column": "*",
...: "function": "count"
...: },
...: "max.number": {
...: "column": "number",
...: "function": "max"
...: }
...: }
In [3]: group_clauses = ["parity"]
In [4]: query = aggregation_query(table, aggs=aggs, group_clauses=group_clauses)
In [5]: print(query)
SELECT test.parity, count(*) AS "count.*", max(test.number) AS "max.number"
FROM test GROUP BY test.parity
we can see the resulting output query is what we expect. Needless to say, the fully fledged SqlAlchemyFdw) implementation handles non-aggregation queries too, and must adequately process the output of all queries, including result-batching support.
Performance impact
Having sketched out the mechanism of our Snowflake FDW, we turn our attention to some actual performance insights. To that
end, we use our command line client sgr to mount
one of the larger schemas (TPCH_SF100) in the sample Snowflake database
available in each trial account.
$ sgr mount snowflake sf100 -o@- <<EOF
{
"username": "user",
"secret": {
"secret_type": "password",
"password": "pass"
},
"account": "bw54298.eu-central-1",
"database": "SNOWFLAKE_SAMPLE_DATA",
"schema": "TPCH_SF100"
}
EOF
By running pgcli $(sgr config -n) we can open a DB shell and execute our queries against the local Splitgraph engine.
Our target will be the table supplier with exactly one million rows. To set a baseline, we will first run our query
without aggregation pushdown enabled, using EXPLAIN to verify that full row fetch will occur beforehand:
sgr@localhost:splitgraph> EXPLAIN SELECT count(*) FROM sf100.supplier
+---------------------------------------------------------------------------------+
| QUERY PLAN |
|---------------------------------------------------------------------------------|
| Aggregate (cost=250000.00..250000.01 rows=1 width=8) |
| -> Foreign Scan on supplier (cost=20.00..0.00 rows=100000000 width=0) |
| Multicorn: |
| SELECT "TPCH_SF100".supplier.s_suppkey |
| FROM "TPCH_SF100".supplier |
| |
| JIT: |
| Functions: 2 |
| Options: Inlining false, Optimization false, Expressions true, Deforming true |
+---------------------------------------------------------------------------------+
EXPLAIN
Time: 0.079s
sgr@localhost:splitgraph> SELECT count(*) FROM sf100.supplier
+---------+
| count |
|---------|
| 1000000 |
+---------+
SELECT 1
Time: 27.699s (27 seconds), executed in: 27.694s (27 seconds)
Trying the same with aggregation pushdown enabled:
sgr@localhost:splitgraph> EXPLAIN SELECT count(*) FROM sf100.supplier
+------------------------------------------------+
| QUERY PLAN |
|------------------------------------------------|
| Foreign Scan (cost=1.00..1.00 rows=1 width=1) |
| Multicorn: |
| SELECT count(*) AS "count.*" |
| FROM "TPCH_SF100".supplier |
| |
+------------------------------------------------+
EXPLAIN
Time: 0.080s
sgr@localhost:splitgraph> SELECT count(*) FROM sf100.supplier
+---------+
| count |
|---------|
| 1000000 |
+---------+
SELECT 1
Time: 0.214s
sgr@localhost:splitgraph>
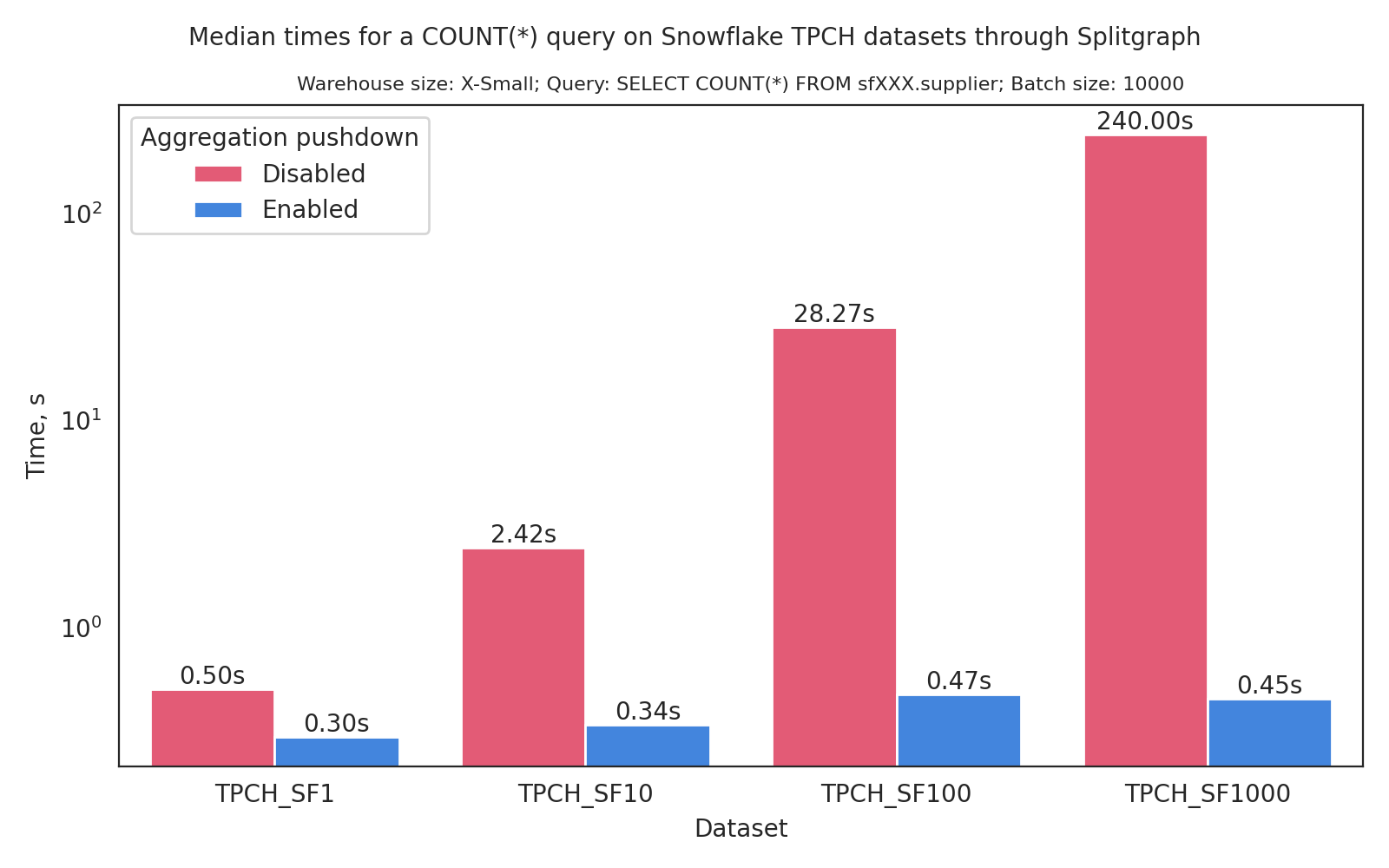
Thus, we see a factor of improvement of more than 100X in the speed of execution. It is worth pointing out that this factor of
improvement scales with the size of the data, which is expected given the behavior in the absence of aggregation pushdown.
For instance, running the same query on TPCH_SF10 (100,000 rows in the supplier table) we see an approximately tenfold speedup,
while running it on TPCH_SF1000 (10,000,000 rows in the supplier table) results in an improvement of effectively three orders of magnitude.
These results are summarized in the graph at the beginning of the article.
Data filtering
Let us now revisit the subject of qualifier pushdown, i.e. handling of WHERE clauses for aggregation queries. Multicorn
already supports qualifier pushdown via the quals argument of the execute method in the Python FDW implementation. However,
before we can safely use it in case of aggregations, we must declare to Multicorn exactly which operators can be pushed down.
This is needed so that Postgres avoids aggregation pushdown when an operator in the WHERE clause does not have an analogue
on the remote data source.
Extending can_pushdown_upperrel which we introduced in the first blog
post, we end up with:
def can_pushdown_upperrel(self):
return {
"groupby_supported": True,
"agg_functions": ["max", "min", "sum", "avg", "count", "count.*"],
"operators_supported": [">", "<"]
}
For simplicity we only specify two supported operators. Revisiting our prototype from earlier, we can now implement the
WHERE clause pushdown alongside the aggregations:
@@ -1,6 +1,8 @@
+import operator
from sqlalchemy.schema import Table, Column, MetaData
from sqlalchemy.types import Integer, String
-from sqlalchemy.sql import select, func
+from sqlalchemy.sql import select, func, and_
_PG_AGG_FUNC_MAPPING = {
@@ -13,7 +15,24 @@ _PG_AGG_FUNC_MAPPING = {
}
-def aggregation_query(table, aggs=None, group_clauses=None):
+OPERATORS = {
+ "<": operator.lt,
+ ">": operator.gt
+}
+
+
+def aggregation_query(table, quals=[], aggs=None, group_clauses=None):
target_list = []
if group_clauses is not None:
@@ -32,6 +51,16 @@ def aggregation_query(table, aggs=None, group_clauses=None):
statement = select(*target_list).select_from(table)
+ clauses = []
+ for qual in quals:
+ operator = OPERATORS.get(qual.operator, None)
+ if operator:
+ clauses.append(operator(table.c[qual.field_name], qual.value))
+ else:
+ raise Exception(f"Qual {qual} not pushed to foreign db!")
+ if clauses:
+ statement = statement.where(and_(*clauses))
+
if group_clauses is None:
return statement
Indeed, testing it out in the console on the same input as before, we get the desired output:
In [1]: from multicorn import Qual
In [2]: quals = [
...: Qual("number", ">", 2),
...: Qual("number", "<", 8)
...: ]
...:
In [3]: q = aggregation_query(table, quals=quals, aggs=aggs, group_clauses=group_clauses)
In [4]: print(q.compile(compile_kwargs={"literal_binds": True}))
SELECT test.parity, count(*) AS "count.*", max(test.number) AS "max.number"
FROM test
WHERE test.number > 2 AND test.number < 8 GROUP BY test.parity
Finally, we can achieve pushdown of some more involved queries:
sgr@localhost:splitgraph> EXPLAIN SELECT o_orderstatus, count(*), avg(o_totalprice)
FROM sf.orders
WHERE o_totalprice > 300000 AND o_orderstatus != 'P'
GROUP BY o_orderstatus
+-------------------------------------------------------------------------------------------------------------------------------------------+
| QUERY PLAN |
|-------------------------------------------------------------------------------------------------------------------------------------------|
| Foreign Scan (cost=1.00..1.00 rows=1 width=1) |
| Multicorn: |
| SELECT "TPCH_SF100".orders.o_orderstatus, count(*) AS "count.*", avg("TPCH_SF100".orders.o_totalprice) AS "avg.o_totalprice" |
| FROM "TPCH_SF100".orders |
| WHERE "TPCH_SF100".orders.o_totalprice > 300000.0 AND "TPCH_SF100".orders.o_orderstatus != 'P' GROUP BY "TPCH_SF100".orders.o_orderstatus |
| |
+-------------------------------------------------------------------------------------------------------------------------------------------+
sgr@localhost:splitgraph> SELECT o_orderstatus, count(*), avg(o_totalprice)
FROM sf.orders
WHERE o_totalprice > 300000 AND o_orderstatus != 'P'
GROUP BY o_orderstatus
+---------------+---------+-----------------+
| o_orderstatus | count | avg |
|---------------+---------+-----------------|
| F | 4116025 | 335437.66336111 |
| O | 4118775 | 335472.48006934 |
+---------------+---------+-----------------+
SELECT 2
Time: 0.152s
WHERE vs HAVING
In case of aggregation queries, data filtering can be applied on the input via WHERE clauses, or the output via
HAVING clauses. At present, our current Multicorn implementation doesn't support pushdown of queries with HAVING clauses.
There is one insightful "exception" to that thanks to a clever PostgreSQL trick—when a HAVING clause references an output target
that is equivalent to an input target, it gets internally converted
to a WHERE clause. An example is a HAVING clause on a column that is also a part of the GROUP BY clause. This is
easily verifiable in our Snowflake FDW, by running EXPLAIN on such a query to see the re-constructed remote query:
sgr@localhost:splitgraph> EXPLAIN SELECT o_orderstatus, max(o_totalprice)
FROM sf.orders
GROUP BY o_orderstatus
HAVING o_orderstatus in ('P', 'F')
+--------------------------------------------------------------------------------------------------------+
| QUERY PLAN |
|--------------------------------------------------------------------------------------------------------|
| Foreign Scan (cost=1.00..1.00 rows=1 width=1) |
| Multicorn: |
| SELECT "TPCH_SF100".orders.o_orderstatus, max("TPCH_SF100".orders.o_totalprice) AS "max.o_totalprice" |
| FROM "TPCH_SF100".orders |
| WHERE "TPCH_SF100".orders.o_orderstatus IN ('P', 'F') GROUP BY "TPCH_SF100".orders.o_orderstatus |
| |
+--------------------------------------------------------------------------------------------------------+
Given that input and output filtering in this case are identical approaches in terms of correctness, Postgres chooses to discard the redundant rows ahead of time, rather then to do it after having performed aggregation processing.
Conclusion
This was a second post in our series on PostgreSQL FDW aggregation pushdown, where we described a practical example utilizing the features we have implemented in the Multicorn framework. In particular, we demonstrated how our SQLAlchemy-based Snowflake FDW makes use of the new capabilities, allowing aggregation and grouping queries to be computed by the Snowflake engine itself, thus circumventing the naive approach of fetching all the rows and only then doing the computation locally.
We provided actual measurements confirming that the naive approach grows prohibitively expensive even for medium-sized tables,
while at the same time the aggregation pushdown technique ensures orders-of-magnitude faster execution times.
Finally, we discussed the importance of detecting early in the planning phase the presence of unsupported operators in
WHERE clauses, so that aggregation pushdown occurs only if the remote data source can apply all the input filtering
qualifiers.
Splitgraph
Made with


on four continents.