Splitgraph has been acquired by EDB! Read the blog post.
PostgreSQL FDW aggregation pushdown part III: Elasticsearch edition
We continue our series on aggregation pushdown and turn our attention to our Elasticsearch FDW. Implementation details, performance considerations as well as a few Postgres tidbits are shared.
Introduction
In this post, we will focus on aggregation pushdown that we implemented in our fork of Elasticsearch FDW, enabling us to use SQL as a query language more efficiently against this search engine.
Having previously laid the foundation of the mechanism's inner workings in part I of the series (Multicorn FDW framework) as well as a first concrete application in part II (our Snowflake FDW), here we explain the peculiarities of the JSON-based Elasticsearch DSL, and how we perform conversion of various PostgreSQL aggregation query constructs.
We also discuss the performance benefits of these changes, demonstrating the substantial speedup of having the remote data source perform the aggregation, versus fetching all the rows before computing the aggregation locally, as is done in the naive, no-pushdown approach. Finally, we explore a number of insightful examples, whereby we show that some more advanced aggregation queries also experience these benefits, courtesy of Postgres' brilliant planning capabilities.
Quick Multicorn recap
Before delving into the actual discussion, let us briefly give a refresher on the Multicorn FDW framework and aggregation pushdown. For a more detailed exposition check out part I of this series.
Multicorn provides a great deal of flexibility for writing novel FDWs, and expedites the implementation. It does so by abstracting away the full details of hooking into Postgres FDW machinery, and only providing the developer with a high level Python interface for final remote API calls and data manipulation.
To accommodate for aggregation pushdown capabilities we've added to Multicorn, we extended this interface so that it now receives arguments denoting aggregation targets, namely grouping clauses as well as information on function-column pairs involved.
Elasticsearch query DSL
The native query language in Elasticsearch is a versatile JSON-based DSL, capable of mimicking a great deal of SQL constructs. Note that running SQL queries on Elasticsearch without FDWs is doable, however this feature is a part of the X-PACK proprietary extension, so it didn't suit our needs.
Therefore our FDW implementation needs to transform the input it gets from Multicorn to a JSON payload to be sent to the remote server, structured in line with the Elasticsearch query syntax.
For the sake of transparency and brevity we will employ the trick we used before—running EXPLAIN on a given statement will print
the resulting converted Elasticsearch query. You can see the full code for generating this
conversion in our Elasticsearch FDW fork repo.
We will use a sample dataset named accounts obtained from an Elastic tutorial
to demonstrate our FDW implementation. Once the dataset is uploaded on the Elasticsearch server, we mount the table on
our local Splitgraph engine using our open-source sgr command line tool:
sgr mount elasticsearch es -c esorigin:9200 -o@- <<EOF
{
"tables": {
"account": {
"options": {
"index": "account"
},
"schema": {
"balance": "integer",
"firstname": "character varying (20)",
"age": "integer",
"state": "character varying (5)",
...
}
}
}
}
EOF
After opening a DB shell on the local Splitgraph engine with pgcli $(sgr config -n), we can start with inspecting the conversion
that takes place for some representative queries.
Basic aggregation query
Let's now inspect a simple example:
sgr@localhost:splitgraph> EXPLAIN SELECT state, max(balance)
FROM es.account GROUP BY state
+-------------------------------------------------------------------------------------------+
| QUERY PLAN |
|-------------------------------------------------------------------------------------------|
| Foreign Scan (cost=1.00..1.00 rows=1 width=1) |
| Multicorn: Elasticsearch query to <Elasticsearch([{'host': 'esorigin', 'port': 9200}])> |
| Multicorn: Query: { |
| "query": { |
| "bool": { |
| "must": [] |
| } |
| }, |
| "aggs": { |
| "group_buckets": { |
| "composite": { |
| "sources": [ |
| { |
| "state": { |
| "terms": { |
| "field": "state" |
| } |
| } |
| } |
| ], |
| "size": 1000 |
| }, |
| "aggregations": { |
| "max.balance": { |
| "max": { |
| "field": "balance" |
| } |
| } |
| } |
| } |
| } |
| } |
+-------------------------------------------------------------------------------------------+
sgr@localhost:splitgraph> SELECT state, max(balance)
FROM es.account GROUP BY state
+-------+-------+
| state | max |
|-------+-------|
| AK | 44043 |
| AL | 49795 |
| AR | 49000 |
...
There are a couple of things worth pointing out:
querycorresponds to record filtering; since we don't use any in this example it's empty for now.aggsholds the actual aggregation targets, with several nested elements in between- the
GROUP BYclause itself is represented via thetermsaggregation over the fieldstate sizedenotes the size of the output; if the output is larger than that we must use pagination to fetch the rest- the other target is represented via the
maxaggregation over the fieldbalanceat the end
Data filtering and pattern matching
In the previous post of this series we went into detail on how data filtering works in combination with aggregations. Due to the impact on the result accuracy, it is imperative to push aggregations only if all involved data filtering operators have an equivalent on the remote server. Consequently, the FDW must declare which operators are supported for pushdown alongside aggregations, so that Multicorn/Postgres can pick an adequate plan.
One interesting example on this topic concerns pattern matching queries. In particular, if we want to support pushdown of
the WHERE clauses involving the ~~ aka LIKE operator, we must also ensure that the corresponding patterns
get converted, given that PostgreSQL uses different symbols than Elasticsearch. It's best to illustrate this with an example:
sgr@localhost:splitgraph> EXPLAIN SELECT count(firstname)
FROM es.account WHERE firstname ~~ 'Su_an%'
+-------------------------------------------------------------------------------------------+
| QUERY PLAN |
|-------------------------------------------------------------------------------------------|
| Foreign Scan (cost=1.00..1.00 rows=1 width=1) |
| Multicorn: Elasticsearch query to <Elasticsearch([{'host': 'esorigin', 'port': 9200}])> |
| Multicorn: Query: { |
| "query": { |
| "bool": { |
| "must": [ |
| { |
| "wildcard": { |
| "firstname": "Su?an*" |
| } |
| } |
| ] |
| } |
| }, |
| "aggs": { |
| "count.firstname": { |
| "value_count": { |
| "field": "firstname" |
| } |
| } |
| } |
| } |
+-------------------------------------------------------------------------------------------+
Note that query element is no longer empty, while the PostgreSQL count gets translated to its Elasticsearch analogue value_count.
More importantly, we see that the pattern for any single character gets converted from _ to ?, while the pattern for a sequence of
any characters is converted from % to * in the wildcard element. In general, we must also handle potential edge cases such as (un-)escaping
patterns using special characters, i.e. converting \%, \_, * and ? into %, _, \* and \? respectively.
Finally, this ensures that we can safely push down such queries (double-checking for the sake of sanity):
sgr@localhost:splitgraph> SELECT count(firstname) FROM es.account
WHERE firstname ~~ 'Su_an%'
+-------+
| count |
|-------|
| 4 |
+-------+
sgr@localhost:splitgraph> SELECT firstname FROM es.account
WHERE firstname ~~ 'Su_an%'
+-----------+
| firstname |
|-----------|
| Susan |
| Susanne |
| Suzanne |
| Susana |
+-----------+
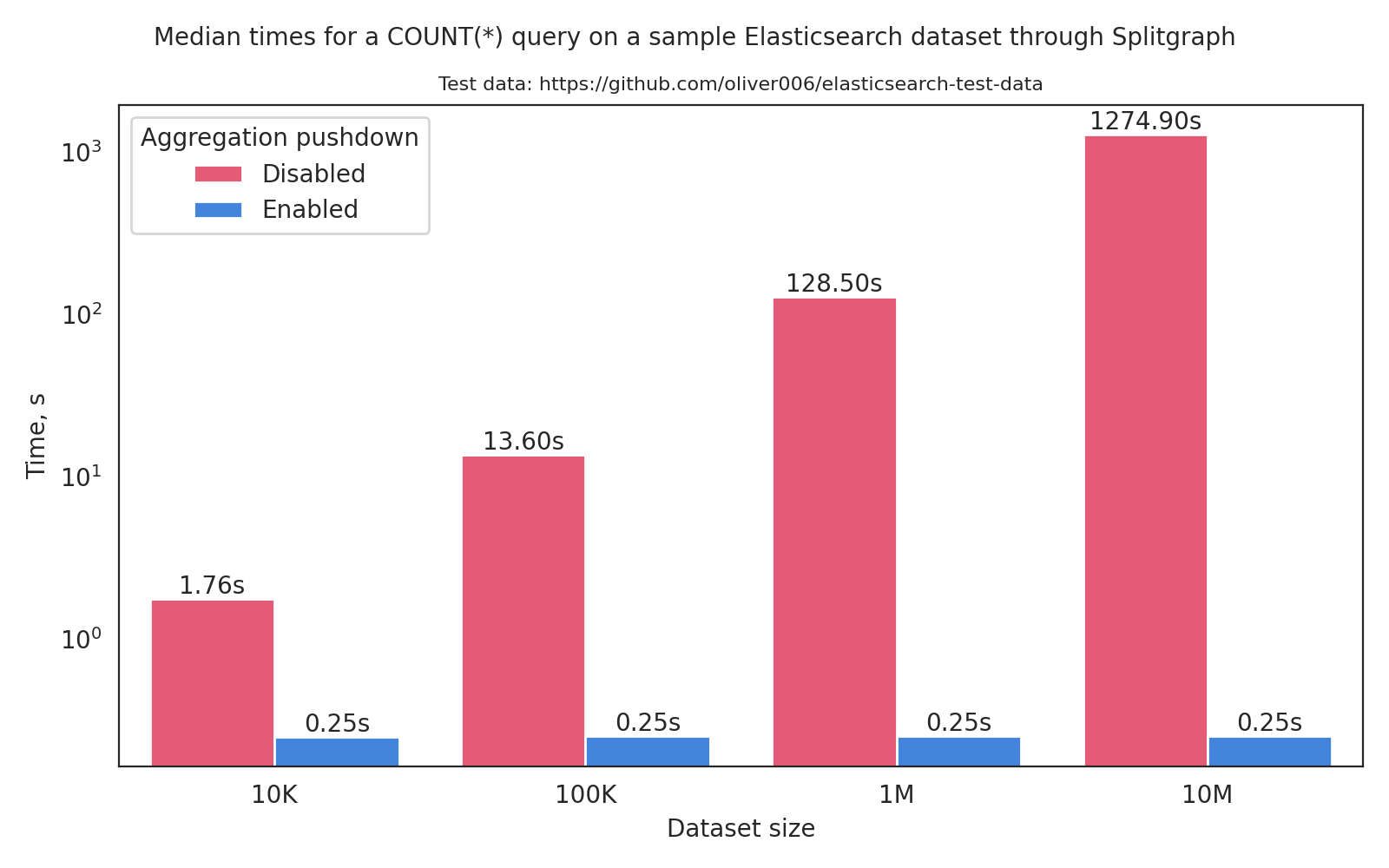
Performance measurements
As with the Snowflake FDW speedup measurements, we tested the
performance improvements of Elasticsearch FDW with and without aggregation pushdown using the SELECT count(*) as benchmark.
This time we also upped the client-server distance which gets reflected in the baseline (i.e. no aggregation pushdown) times.
Since es.account has only 1000 records, we employed the great es_test_data.py
for seeding our Elasticsearch server with larger sample datasets, ranging from 10K to 10M in size.
After mounting the table using sgr mount elasticsearch command as before we executed a number of queries. The summary
of the results is given in the table below (using median times):
| ES index size | W/O agg pushdown | W agg pushdown |
|---|---|---|
| 10K | 1.761 | 0.251 |
| 100K | 13.6 | 0.252 |
| 1M | 128.5 | 0.253 |
| 10M | 1274.9 | 0.252 |
As expected, we see dramatic performance improvements when aggregations get pushed down, scaling with the remote dataset size.
Subquery pushdown
Having demonstrated the speedup from the aggregation pushdown, we return to our es.account dataset, and focus our
attention on some unexpected perks which caught us by surprise. Specifically, we are referring to a remarkable ability
of Postgres to push down subqueries in advanced expressions and then perform any remaining computation locally, thus
significantly improving performance.
Plain subquery
Consider the following, arguably a bit contrived example: what are the all unique minimum ages across all states?
sgr@localhost:splitgraph> EXPLAIN SELECT DISTINCT min_age FROM(
SELECT state, min(age) as min_age, max(balance)
FROM es.account GROUP BY state
) AS t
+-------------------------------------------------------------------------------------------------------------+
| QUERY PLAN |
|-------------------------------------------------------------------------------------------------------------|
| Unique (cost=1.02..1.03 rows=1 width=4) |
| -> Sort (cost=1.02..1.02 rows=1 width=4) |
| Sort Key: t.min |
| -> Subquery Scan on t (cost=1.00..1.01 rows=1 width=4) |
| -> Foreign Scan (cost=1.00..1.00 rows=1 width=1) |
| Multicorn: Elasticsearch query to <Elasticsearch([{'host': 'esorigin', 'port': 9200}])> |
| Multicorn: Query: { |
| "query": { |
| "bool": { |
| "must": [] |
| } |
| }, |
| "aggs": { |
| "group_buckets": { |
| "composite": { |
| "sources": [ |
| { |
| "state": { |
| "terms": { |
| "field": "state" |
| } |
| } |
| } |
| ], |
| "size": 1000 |
| }, |
| "aggregations": { |
| "min.age": { |
| "min": { |
| "field": "age" |
| } |
| } |
| } |
| } |
| } |
| } |
+-------------------------------------------------------------------------------------------------------------+
By inspecting the resulting Elasticsearch query, you can see that Postgres did in fact go for a pushdown of the inner (sub)query.
On top of this, Postgres is more than smart enough not to pushdown something it knows isn't needed in the output, namely
max(balance).
When we execute this query, we see that the DISTINCT clause was indeed applied, and the final result is accurate:
sgr@localhost:splitgraph> SELECT DISTINCT min_age FROM(
SELECT state, min(age) as min_age, max(balance)
FROM es.account GROUP BY state
) AS t
+---------+
| min_age |
|---------|
| 20 |
| 21 |
| 22 |
| 23 |
| 24 |
+---------+
CTE subquery
Moving on, we now examine a more meaningful example—finding the age of the oldest person among all the youngest persons in each state. To perform this query, we use a common table expression, first getting the minimum age per state, and then taking the maximum of that:
sgr@localhost:splitgraph> EXPLAIN WITH sub_agg AS (
SELECT state, min(age) as min_age
FROM es.account GROUP BY state
)
SELECT max(min_age) FROM sub_agg
+-------------------------------------------------------------------------------------------------+
| QUERY PLAN |
|-------------------------------------------------------------------------------------------------|
...
| Multicorn: Query: { |
...
| "terms": { |
| "field": "state" |
| } |
...
| "min": { |
| "field": "age" |
| } |
...
For brevity we omitted the boilerplate query elements, and only left the crucial ones. As you can see, the query is identical to the one above, because the subqueries are effectively the same. Actually executing the query:
sgr@localhost:splitgraph> WITH sub_agg AS (
SELECT state, min(age) as min_age
FROM es.account GROUP BY state
)
SELECT max(min_age) FROM sub_agg
+-----+
| max |
|-----|
| 24 |
+-----+
reveals that Postgres performed the final aggregation on top of the pre-aggregated result it got from Elasticsearch.
JOIN subqueries
Finally, the most elaborate example—joining across two aggregation subqueries. In general, Multicorn doesn't support JOIN
pushdown on it's own, let alone in combination with aggregations. However in these types of cases, Postgres is able to
make the most out of the capabilities at hand, and join across the pre-aggregated response from the remote data source.
There is a reasonable question behind this example too, and it reads:
- which are the pairs of states...
- where the youngest person in one state has the same age as the oldest person in the other state...
- out of all the people with a balance over 35,000?
sgr@localhost:splitgraph> EXPLAIN
SELECT t1.state, t2.state, t1.min FROM (
SELECT state, min(age)
FROM es.account
WHERE balance > 35000
GROUP BY state
) AS t1
INNER JOIN (
SELECT state, max(age)
FROM es.account
WHERE balance > 35000
GROUP BY state
) AS t2
ON t1.min = t2.max
+-------------------------------------------------------------------------------------------------+
| QUERY PLAN |
|-------------------------------------------------------------------------------------------------|
...
| Multicorn: Query: { |
...
| "balance": { |
| "gt": 35000 |
| } |
...
| "terms": { |
| "field": "state" |
| } |
...
| "min": { |
| "field": "age" |
| } |
...
| Multicorn: Query: { |
...
| "balance": { |
| "gt": 35000 |
| } |
...
| "terms": { |
| "field": "state" |
| } |
...
| "max": { |
| "field": "age" |
| } |
...
Interestingly, Postgres now performs not one, but two pushdowns to get the output for each of the two subqueries. Finally, executing the query gives us the answer to our question:
sgr@localhost:splitgraph> SELECT t1.state, t2.state, t1.min as min_max
FROM (
SELECT state, min(age)
FROM es.account
WHERE balance > 35000
GROUP BY state
) AS t1
INNER JOIN (
SELECT state, max(age)
FROM es.account
WHERE balance > 35000
GROUP BY state
) AS t2
ON t1.min = t2.max
+-------+-------+---------+
| state | state | min_max |
|-------+-------+---------|
| DE | NV | 30 |
| FL | CT | 27 |
| OR | OR | 29 |
+-------+-------+---------+
Conclusion
Building on our work of extending Multicorn with aggregation pushdown capability, we covered the second real-world example that we use at Splitgraph. We showed how we achieve the translation of various PostgreSQL aggregation query constructs into the JSON-based Elasticsearch DSL payloads, and demonstrated actual performance improvements of this features.
Finally, we've used Multicorn's capability of planning introspection to peek inside the approach Postgres takes on complex queries with aggregations. This revealed that even when it's unable to push down the entire query, Postgres takes advantage of any opportunity for subquery aggregation pushdown, followed by performing the final processing locally much more efficiently.
Splitgraph
Made with


on four continents.