Splitgraph has been acquired by EDB! Read the blog post.
(Ab)using CDNs for SQL queries
A deep dive into how we designed Seafowl's REST API to be HTTP cache and CDN friendly, including some discussion of ETags and other HTTP cache mechanics.
Introduction
Seafowl is a database for analytics at the edge: data-driven Web visualizations, dashboards and notebooks that require low-latency execution of analytical queries.
To put it plainly, Seafowl lets you stop building these kinds of custom APIs for every visualization in your application:
curl https://custom-api.myproject.io/basic_summary?country_of_import=BRAZIL&commodity=COFFEE&calculate=country_of_production,avg_volume,total_entries
and execute plain SQL queries straight from the user's browser instead:
curl https://demo.seafowl.io/q \
-XPOST -H "Content-Type: application/json" \
-d@- <<EOF
{"query": "SELECT \
country_of_production, \
AVG(volume) AS avg_volume, \
COUNT(*) AS total_entries \
FROM supply_chains \
WHERE country_of_import = 'BRAZIL' \
AND commodity = 'COFFEE' \
GROUP BY 1 ORDER BY 2 DESC"}
EOF
The key feature of Seafowl is being CDN- and HTTP-cache friendly. Seafowl's SQL query results can be cached by CDNs like Cloudflare or HTTP caches like Varnish (as well as the end user's browser cache).
This decreases the latency of applications that are powered by Seafowl, as well as the resource requirements for running a Seafowl instance.
Try it out
You can run Seafowl on any infrastructure provider. For this example, we have a sample Seafowl deployment running on Fly.io behind Cloudflare:

This is an Observable notebook backed by a 3M row dataset served by this deployment (thanks to Trase for the data):
Because you loaded this page, the result for the aggregation queries that produced these visualizations is already cached in your browser. On first load, it should have also been served from Cloudflare's edge cache.
Press F12 to go to your browser's Developer Tools and go to the Network tab. If
you refresh this page now, you should see HTTP requests to
https://demo.seafowl.io being cached by your browser.
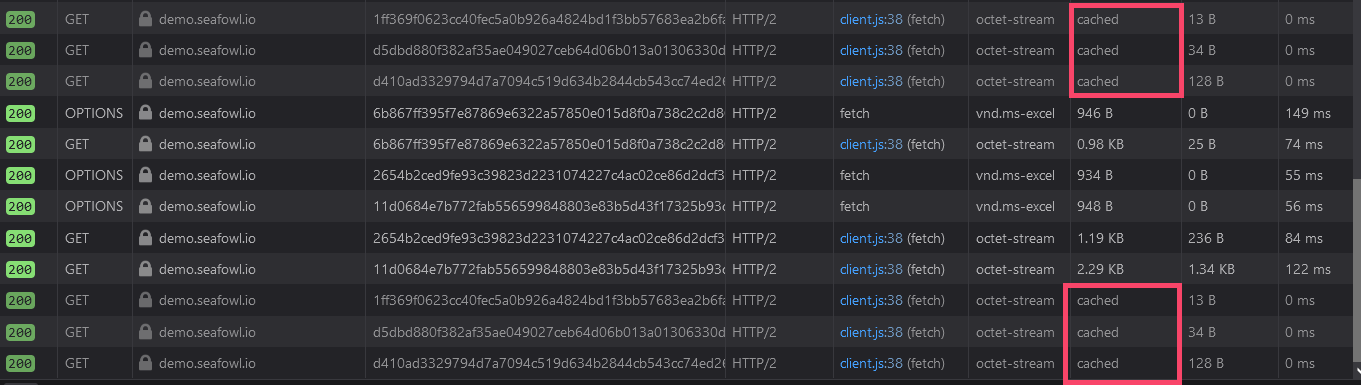
You can also check "Disable Cache" and refresh the page again: you should see
requests going directly to the source. If you inspect one of them, it should
have a CF-Cache-Status: HIT header, meaning it was cached by Cloudflare.
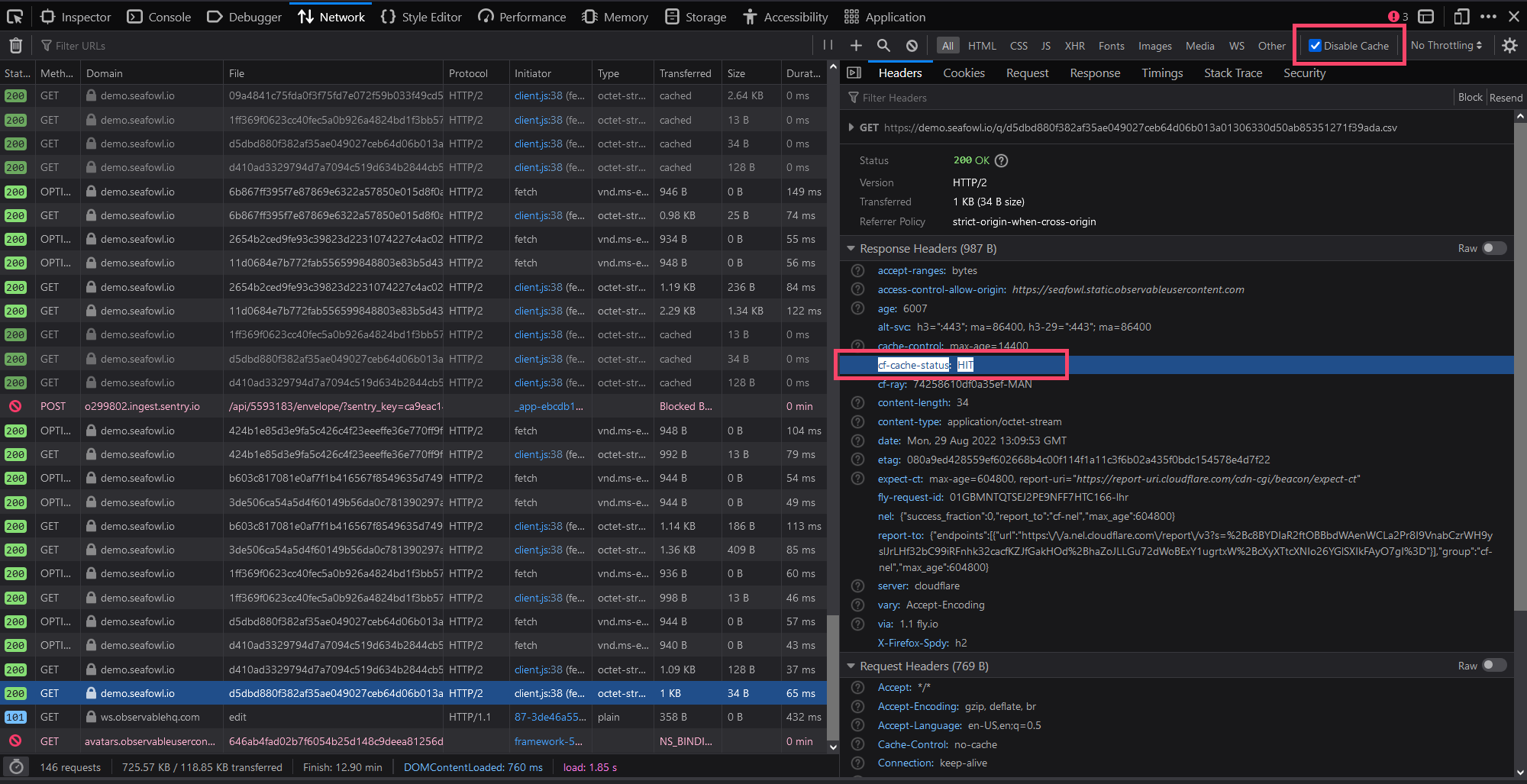
So, how does this work? Let's dive in!1
Query results are static assets
HTTP has provisions for caching static assets. If we can make our query results behave like other assets (images, JavaScript, documents), we can benefit from caching as well.
How do caches handle static assets? They:
- use the URL of the asset as part of the cache key
- usually only cache GET requests
- cache based on the MIME type or the file extension (Cloudflare)
Seafowl is designed to power Web applications backed by slowly-changing data. This means we can make some assumptions that make this easier to build.
In particular, we can assume that the result of a single SQL query is identified by the text of the SQL query (what if the query result changes because the source data changed? More on that later).
This means also assuming that the original SQL query doesn't contain
volatile functions (like random()).
Let's put the query in the URL!
Update (May 2023): As of Seafowl 0.4.1 this approach, due to it being the simplest one,
is also supported,
despite some of the potential shortcomings discussed in this paragraph.
A first approximation of getting this to work is putting the query text into the URL. We can URI-encode special characters in the query to make it a valid URL. However, this has a couple of drawbacks.
First, we can hit URL length limits. These vary between browsers and HTTP intermediaries (like CDNs). The limit can be anywhere from 2KB to 64KB (source), depending on the exact implementation.
It also looks suspicious. A SQL query inside of the URL looks too much like an attempt at SQL injection. We haven't explicitly confirmed it, but it could be something a Web application firewall or an intrusion detection system would flag.
Let's put something else in the URL?
How about we use a string that changes with the query but isn't as long as the query itself? Something like a SHA-256 hash of the query?
This raises another question: how does the server now recover the original query to actually execute it? There are two ways we can do this.
We can pass the original query as a GET request body. This is unusual but is sometimes used by servers like ElasticSearch. RFC7231 doesn't explicitly forbid it, but does warn against using it:
A payload within a GET request message has no defined semantics; sending a payload body on a GET request might cause some existing implementations to reject the request.
Unfortunately, it's also unsupported by some clients that can reject or quietly drop the GET body, to the point where the Fetch standard explicitly disallows it (see the discussion in the GitHub issue).
This leaves us with the other option: using an HTTP header. We can pass the original query as the header, percent-encoding it as well. HTTP headers support some characters that would normally have to be encoded in a URL, like spaces. This means that we only need to encode non-ASCII characters and newlines, decreasing the length of the query (HTTP headers have length limits too!).
Seafowl supports both of these methods. For example, with the HTTP header:
curl -H "X-Seafowl-Query: SELECT 'Hello, Seafowl'" \
https://demo.seafowl.io/q/7468d08fa2c3a2dc59905511dc478784a550e2d4ad67d101802a6411099d690f
{"Utf8(\"Hello, Seafowl\")":"Hello, Seafowl"}
You can also bypass the cached GET API altogether and execute queries with POST requests instead:
curl https://demo.seafowl.io/q \
-XPOST -H "Content-Type: application/json" \
-d@- <<EOF
{"query": "SELECT 'Hello, Seafowl'"}
EOF
Client code
Instead of making a plain HTTP request, the client does have to do extra work by hashing the query and URL-encoding it. This, however, is very straightforward to do.
We have a sample Observable client that implements the DatabaseClient specification.
You can also use curl and Bash:
#!/bin/bash -e
SEAFOWL_HOST = "http://localhost:8080"
query=$1
hash=$(echo -n "$query" | sha256sum | cut -f 1 -d " ")
curl -v\
-H "X-Seafowl-Query: ${query}" \
"$SEAFOWL_HOST/q/$hash"
Or Node.js, or run JavaScript from the browser.
Do we need to normalize the query?
You'll notice that multiple queries with the same semantic meaning but different text (for example, with different formatting) will hash to different values, resulting in a cache miss.
This is not that big of a deal. If you control the application that queries Seafowl, you also control the shape of SQL queries it will make and will be able to minimize cache misses. You can also use the changes in the formatting (or add comments to your SQL query) as an "escape hatch" to bust the cache and force a query to re-execute.
What about invalidation?
What happens when the source dataset changes and we need to update the query result? Luckily, the HTTP standard has provisions for that: it supports "Entity tags", or ETags.
An ETag is something an HTTP server can attach to a response, denoting the version of the resource that has been served. Clients (including HTTP caches and CDNs) can then use this ETag to make a conditional request:
- give the ETag back to the server as an
If-None-Matchheader - the server will return the resource only if the version provided by the server is newer than the provided
- otherwise, it will return a
304 Not ModifiedHTTP response ETag.
Seafowl keeps track of the latest version of each table. When you write data to Seafowl, it bumps the table version. It then uses the version numbers of all tables participating in a query to compute the ETag, which it attaches to all responses to its cached GET API.
Putting it all together
Let's now take a look at how this works with Seafowl running behind a CDN. In this case, we're using our demo deployment running on Fly.io behind Cloudflare, but you can use any other CDN or an HTTP cache like Varnish, or no CDN at all and rely on your user's browser cache.
Request 1: cache miss

When a browser requests a query from Seafowl's GET API for the first time, it's uncached by Cloudflare.
Cloudflare forwards the query to the origin (Seafowl). Seafowl executes it and computes an ETag for the latest version of all tables that participated in the query.
Cloudflare caches the ETag and the response and forwards it to the client. The client's browser caches the response as well.
We do a small hack here: instead of requesting the query hash, we also append a
.csv extension to the URL. This is because by default, Cloudflare only
caches certain extensions
and this tricks it into caching our response. The extension is discarded by
Seafowl (it always returns responses in the JSON Lines format).
Request 2: cache hit
If another browser (or the same browser with the browser cache disabled)
requests the same query within a certain time window (a few hours), Cloudflare
won't forward it to the Seafowl origin. Instead, it serves it from its own
cache. We can see this happened because Cloudflare returns a
CF-Cache-Status: HIT header.
Request 3: cache revalidation

Let's now say some time has passed since the original query and the CDN needs to revalidate the response to make sure it's still up to date.
Cloudflare makes a conditional HTTP request with the If-None-Match header
set to its stored ETag. Seafowl inspects the inbound ETag in the If-None-Match
header, calculates the current ETag for a given query and compares them.
This operation is much more lightweight than actually executing the query (where Seafowl would need to potentially download and scan through all partitions).
In this case, the source dataset hasn't changed and Seafowl responds with a
304 Not Modified HTTP response (without the query result).
Cloudflare returns the cached response back to the user with a
CF-Cache-Status: REVALIDATED header to note that it has revalidated the
response and it's still up to date.
Request 4: cache invalidation

Finally, let's say the source data has been updated. The user's browser makes the same request to Cloudflare and Cloudflare makes the same conditional request to Seafowl with a stale ETag.
In this case, Seafowl's computed ETag will be different from the one passed to it by Cloudflare. That is, the response has expired. Seafowl re-executes the query and returns the new result to Cloudflare, with a new ETag.
Cloudflare caches the new response and the new ETag. Finally, it forwards the
response to the user's browser with a CF-Cache-Status: EXPIRED header to note
that the response was stale and got reloaded from the origin.
Conclusion
And that's it! With a few tricks we made our HTTP API cache-friendly. Any HTTP cache or a CDN can now cache Seafowl query results and invalidate them when the source data changes. This makes applications powered by Seafowl respond faster and require less resources.
If you're interested in learning more about Seafowl, feel free to check out our Observable demo, go through our quickstart or through a longer tutorial in which you'll deploy Seafowl to Fly.io, put it behind Cloudflare or Varnish and reproduce our Observable demo notebook.
Other questions
Bringing the data or the query results to the edge?
You might ask, why go through all this trouble to cache query results when we could deploy our application at the edge instead? The key insight lies in how analytical queries work:
- They usually reduce a big (millions/billons of rows, a few GB of data) dataset into a small (hundreds/thousands of rows, a few KB) summarized response
- They take hundreds of milliseconds or seconds instead of milliseconds or microseconds (like transactional queries would)
Let's say:
- an analytical query normally takes 500ms
- the latency to the origin is 100ms
- the latency to the edge location is 10ms
In that case, executing the query closer to the user would turn a 600ms end-to-end latency to 510ms, which is not a noticeable improvement. It also has to come at the expense of replicating the data and running the query engine at the edge location2.
However, if a query result is cacheable, caching it at the edge instead of at the origin would bring a 100ms response time down to 10ms.
Simply put, analytical queries normally take too much time to benefit from moving the execution closer to the user.
Using a non-HTTP cache?
An alternative to using HTTP for this would be implementing caching in Seafowl itself or deploying a cache like Redis or Memcached. However, this would also mean either requiring some scratch disk space for a Seafowl deployment to store the query result cache or requiring Seafowl users to run caches at edge locations.
We'd also need to write a more sophisticated client for querying Seafowl in order to get query results cached in your application user's browser.
Using HTTP caches gives us all of this for free, including the ability to rely on existing HTTP infrastructure.
How does this break?
There are a few known issues with this kind of caching as we implemented it:
- Updating the definition of a user-defined WASM function doesn't invalidate the cache for queries that use those functions (GitHub issue)
- Updating a table and then applying an opposite update still changes the table version ID, even though the content of the table is effectively unchanged (GitHub issue)
- Queries that reference external tables don't support the invalidation mechanism
- You can't currently change the Cache-Control headers sent out by Seafowl (GitHub issue)
- This is a longer-form version of our tutorial and the documentation for the cached GET API feature.↩
- In the extreme case, the "edge location" is the user's browser itself (see DataStation or this blog post), which works pretty well if the query engine doesn't need to load more than a few MB of data (because it's on the user's machine already or because it's small enough to begin with).↩
Splitgraph
Made with


on four continents.