Splitgraph has been acquired by EDB! Read the blog post.
Port 5432 is open: introducing the Splitgraph Data Delivery Network
We launch the Splitgraph Data Delivery Network: a single endpoint that lets any PostgreSQL application, client or BI tool to connect and query over 40,000 public datasets hosted or proxied by Splitgraph.
Today, we are announcing the next step for Splitgraph: the Splitgraph Data Delivery Network.
The Splitgraph DDN is a single SQL endpoint that lets you query over 40,000 public datasets hosted on or proxied by Splitgraph.
You can connect to it from most PostgreSQL clients and BI tools without having to install anything else. It supports all read-only SQL constructs, including filters and aggregations. It even lets you run joins across distinct datasets.
In this post, we will give you a quick introduction to the DDN as well as discuss how it works behind the scenes and our plan for its future.
Usage
Connecting
The endpoint is at postgresql://data.splitgraph.com:5432/ddn. You will need a Splitgraph API key and secret to access it.
You don't need to install anything to use the endpoint. If you go to your Splitgraph account settings, you can generate a pair of credentials. You can then plug them into your SQL client.
If you're already using the sgr client and had registered for Splitgraph before, you can check your .sgconfig file for the API keys. You can also upgrade your client to version 0.2.0 with sgr upgrade and run sgr cloud sql to get a libpq-compatible connection string.
Installing Splitgraph locally will let you snapshot these datasets and use them in Splitfiles.
There are more setup methods available in our documentation. This includes connecting to Splitgraph with clients like DBeaver, BI tools like Metabase or Google Data Studio or even other databases through ODBC.
Workspaces
When you connect to Splitgraph, your SQL client will show you some schemas. These are data repositories featured on our explore page as well as datasets that you upload to Splitgraph.
We call this feature "workspaces". It works by implementing the ANSI information schema standard. We'll expand on workspaces more in the future. For example, we'll let you:
- bookmark repositories that you want to show up in your workspace
- allow you to have multiple workspaces and manage access to them
- search for Splitgraph repositories directly from your SQL client.
Running queries
You can run queries on Splitgraph images by referencing them as PostgreSQL schemata: namespace/repository[:hash_or_tag]. By default, we query the latest tag.
For example, if you want to query the cityofchicago/covid19-daily-cases-deaths-and-hospitalizations-naz8-j4nc repository, proxied by Splitgraph to Socrata, you can run:
SELECT * FROM
"cityofchicago/covid19-daily-cases-deaths-and-hospitalizations-naz8-j4nc".covid19_daily_cases_deaths_and_hospitalizations
We let you use SQL SELECT and EXPLAIN statements. You can use any SQL clauses, including group-bys, aggregations, filters and joins. Splitgraph pushes filters down to the origin data source.
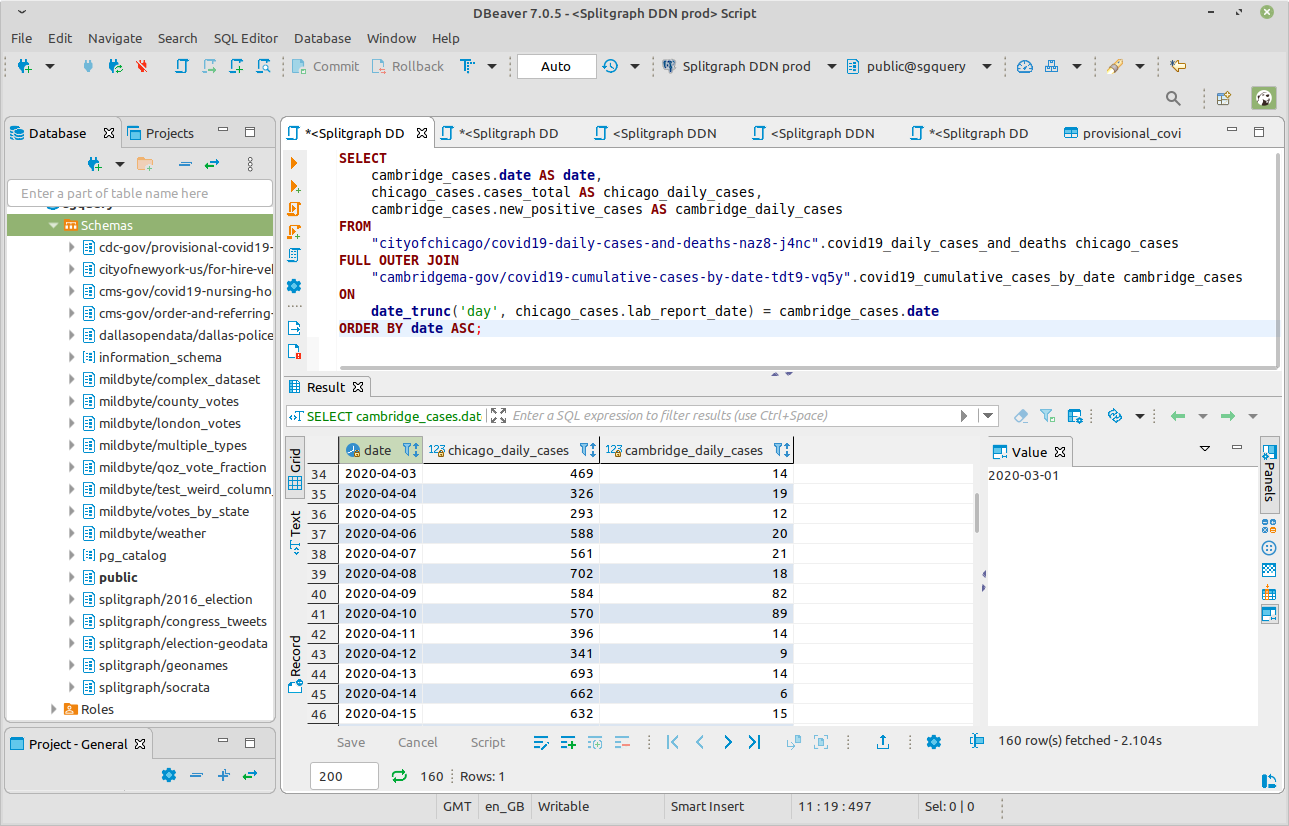
This sample query that we used in our Metabase demo runs a JOIN between two datasets:
SELECT
cambridge_cases.date AS date,
chicago_cases.cases_total AS chicago_daily_cases,
cambridge_cases.new_positive_cases AS cambridge_daily_cases
FROM
"cityofchicago/covid19-daily-cases-deaths-and-hospitalizations-naz8-j4nc".covid19_daily_cases_deaths_and_hospitalizations chicago_cases
FULL OUTER JOIN
"cambridgema-gov/covid19-case-count-by-date-axxk-jvk8".covid19_case_count_by_date cambridge_cases
ON
date_trunc('day', chicago_cases.lab_report_date) = cambridge_cases.date::timestamp
ORDER BY date ASC;
This will join the data between two distinct Socrata data portals (Chicago, IL and Cambridge, MA).
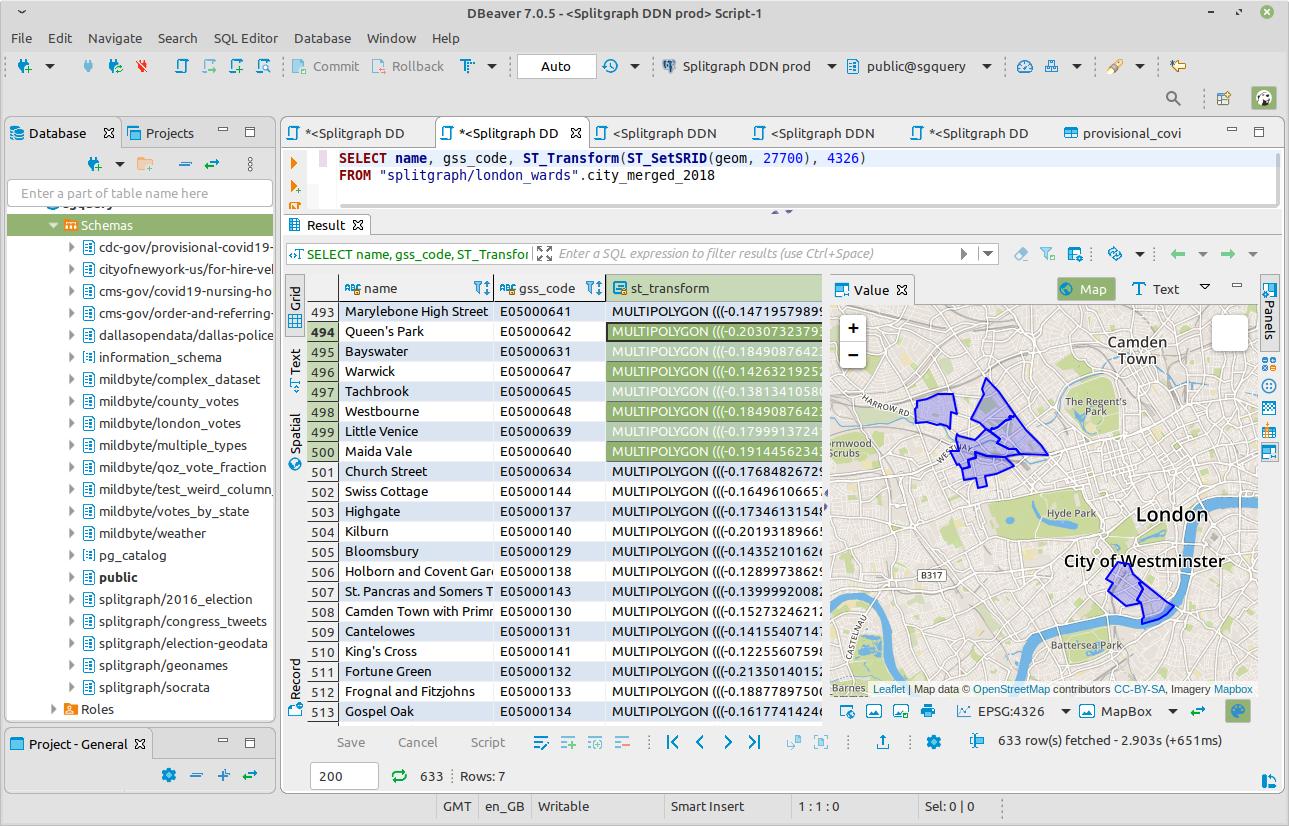
We also support PostGIS, letting you query and visualize geospatial data. For example, you can query the London ward boundary data image as follows:
SELECT
name,
gss_code,
-- Transform to https://epsg.io/4326 to plot on the map
ST_Transform(ST_SetSRID(geom, 27700), 4326),
-- Transform to https://epsg.io/3035 for metric units (for area)
ST_Area(ST_Transform(ST_SetSRID(geom, 27700), 3035)) / 1000000 AS area_sqkm
FROM
"splitgraph/london_wards".city_merged_2018
ORDER BY gss_code ASC;
There are more sample queries on our Connect page.
Behind the scenes
The Splitgraph Data Delivery Network is the result of all the work we've put into the sgr client and the Splitgraph Core code over the past two years.
It would also have not been possible without some other open source technologies.
We use PostgreSQL foreign data wrappers. They let us perform query execution and planning across federated data sources. We wrote about foreign data wrappers before: they're powerful and underused!
We manage connections using a fork of PgBouncer, a PostgreSQL connection pooler. Our fork lets us perform authentication outside of PostgreSQL. We can issue and revoke API keys without having to manipulate database roles. Several inbound Splitgraph users can run queries as a single PostgreSQL user.
We also use PgBouncer to transform queries on the fly. We rewrite clients' introspection queries and let them reference Splitgraph images as PostgreSQL schemata.
Each client essentially operates within its own isolated virtual database. The obvious implementation of this would be spinning up one database per client. But our query transformations let us do this at a much lower infrastructure cost. We also use this feature to inspect and drop unwanted queries on the fly.
Finally, we use our own sgr client to orchestrate this. Splitgraph engines power the data delivery network. They manage foreign data wrapper instantiation and querying Splitgraph images via layered querying. In the future, we will use Splitgraph's storage format to snapshot remote datasets or cache frequent queries.
Future and roadmap
There are a lot of directions we would like to pursue with Splitgraph.
You will be able to use Splitgraph to replace some of your data lake or ETL pipelines and query the data at source. This is similar to the idea of "data virtualization". But, unlike other software in this space, Splitgraph uses an open PostgreSQL protocol. This makes it immediately compatible with most of your BI tools and dashboards. It won't lock you into a proprietary query language.
We will soon have the ability to add external repositories to public or on-premises Splitgraph data catalogs. You will be able to query any dataset indexed in this catalog over the single SQL endpoint or our REST API. You will be able to even use these datasets in Splitfiles. This will let you define reproducible transformations on your data, enrich it with public datasets and track lineage.
You will be able to use Splitgraph as an SQL firewall and a rewrite layer. You won't need to use views to set up access policies for your data warehouse. Data consumers won't need to manage credentials to disjoint data silos. Splitgraph can inspect proxied queries and enforce granular access policies on individual columns. It will even be able to do PII masking and access auditing.
The single SQL endpoint is well suited for a data marketplace. Data vendors currently ship data in CSV files or other ad-hoc formats. They have to maintain pages of instructions on ingesting this data. With Splitgraph, data consumers will be able to acquire and interact with data directly from their applications and clients.
Conclusion
Today, we launched the Splitgraph Data Delivery Network. It's a seamless experience of a single database with thousands of datasets at your fingertips, compatible with most existing clients and BI tools.
If you wish to try it out, you can get credentials to access it in less than a minute: just head on to the landing page.
We're also building towards a "Splitgraph Private Cloud" product that will let setup your own private Splitgraph cluster, managed by us and deployed to the cloud region of your choice. Contact us if you're interested!
Splitgraph
Made with


on four continents.