Splitgraph has been acquired by EDB! Read the blog post.
How we built a ChatGPT plugin for Splitgraph
We built a ChatGPT plugin for querying Splitgraph without writing SQL. Along the way, we discovered a better way to write LLM-powered applications.
Try out the Splitgraph plugin for ChatGPT! Installation from the plugin store for ChatGPT Plus users is simple. Note that you will be prompted to log in using your Google account.
Some example questions to try:
- What summer meals programs are available for students in Texas?
- What is the distribution of COVID-19 vaccinations by age group?
Alternatively, check out the plugin's source on GitHub. If you're interested in how the plugin works and what we discovered as we built it, read on!
Introduction
ChatGPT's ability to produce working Python code, write essays for college English class or summarize business reports is impressive. But as a language model, GPT has the limitation that it can only use the data it was trained on in addition to the prompt sent by the user to generate its response. In order to reference events since GPT's training cutoff in September 2021, access web pages or perform mathematical calculations, ChatGPT needs to use plugins.
The Splitgraph Data Delivery Network (DDN) hosts over 40,000 public datasets covering a wide range of topics from traffic accidents in Fort Worth, Texas to marijuana sales in Colorado, all queryable via SQL. A ChatGPT plugin which answers natural language questions using this data could become a powerful tool for those who can't write SQL queries. We decided to turn our language-model augmented retrieval demo into a ChatGPT plugin and share our experience in this blog post!
How does a ChatGPT plugin work?
OpenAI provides a helpful demo retrieval plugin which provides a working example, but which can seem a bit complex at first glance.
A ChatGPT plugin is simply a web service with a ChatGPT-specific ai-plugin.json manifest file.
This file describes how to present and invoke the plugin. It contains:
- The URL of the OpenAPI description of the API.
- The authentication method used for HTTP requests made by ChatGPT to the plugin's API.
- The prompt instructing GPT when the plugin should be consulted in the
description_for_modelfield. - Branding, a human-friendly description, and company information for the plugin (logo URL, developer contact, legal, etc.)
Once a plugin is approved for inclusion in the ChatGPT plugin store, its ai-plugin.json manifest cannot be changed. Doing so requires restarting the approval process.
Fortunately, in the development stage it's OK to change the manifest file. This is particularly important when iterating on the description_for_model prompt,
which is the primary source ChatGPT consults in order to determine whether a plugin should be used to generate a response, and if so, how.
A ChatGPT plugin's OpenAPI endpoints can accept and return structured JSON data similar to the example retrieval plugin or Markdown-formatted text. Plugins have limited control over what ChatGPT's end users see, as their response is filtered through the language model, which may decide to omit or reword parts of the plugin's response.
What should the Splitgraph ChatGPT plugin do?
It's clear that the Splitgraph ChatGPT plugin should query the DDN to help ChatGPT generate responses without requiring the user to manually write SQL queries. What is not immediately apparent is what input ChatGPT provides, and what responses it expects to receive. Luckily, it's easy to see how ChatGPT communicates with plugins by clicking on the caret to the right of the "Used plugin" message:
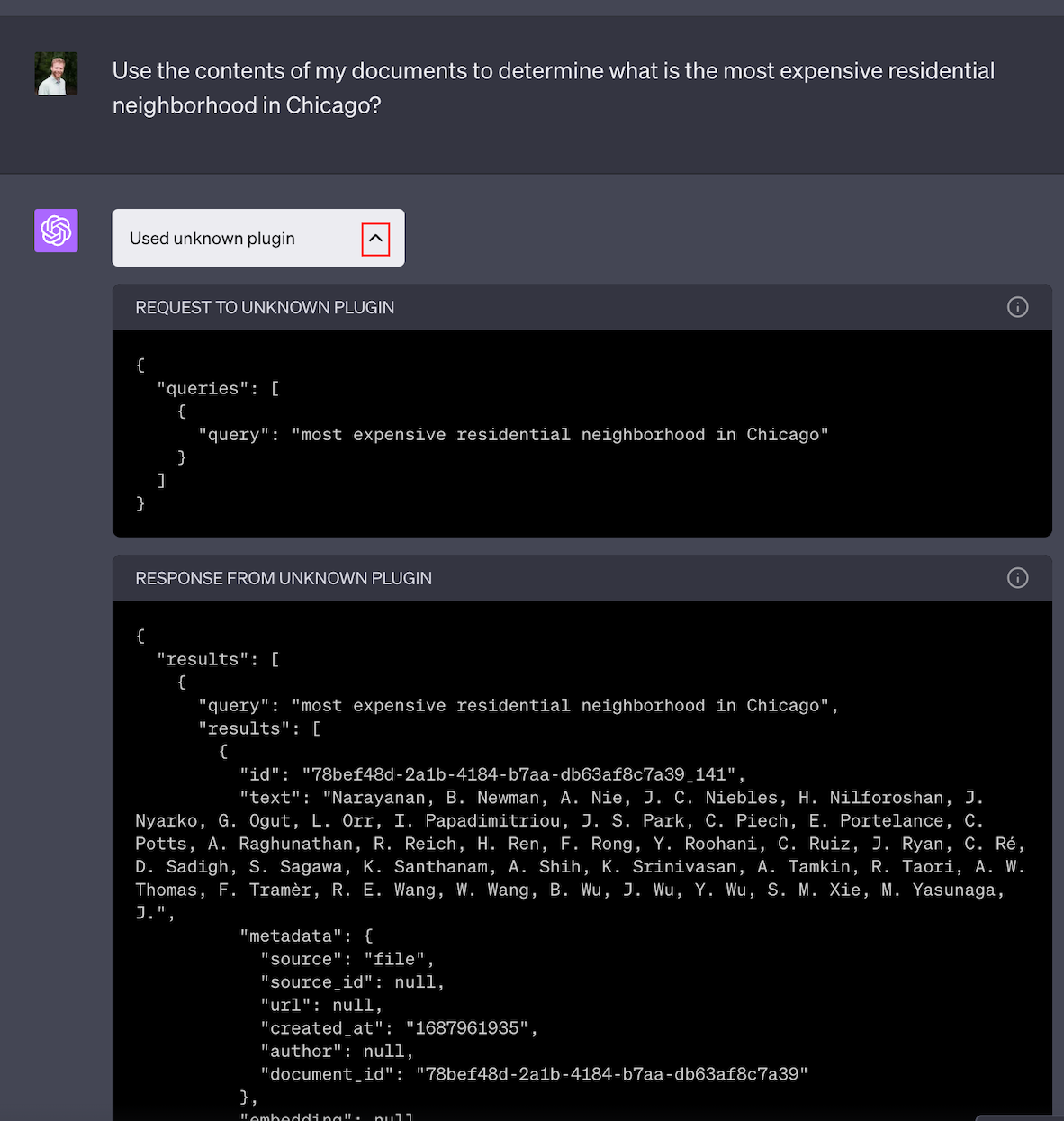
The example retrieval plugin provides a query endpoint which simply returns the JSON representation of the most relevant document fragments based on their embeddings.
Our first attempt at a Splitgraph plugin had a similar interface consisting of a single endpoint expecting a user prompt, returning the DDN's response to the prompt-inspired SQL query as a markdown table.
Plugin architecture: GPT sandwich
Since Splitgraph is queried via SQL, our initial approach was to use the GPT API to generate SQL much the same way we did in our language-model augmented retrieval demo.
Consider the question,
How many public library branches operate in Chicago?
Our "GPT sandwich" plugin received the user's prompt from ChatGPT and invoked the GPT API to generate an SQL query to execute on the DDN (hence the name).

As demonstrated in this ChatGPT conversation, the "GPT sandwich" plugin was capable of providing a useful response. Unfortunately, the communication between the plugin and the GPT API is hidden from the ChatGPT user.
The prompt used by the plugin to request a completion from the GPT API was:
You are a PostgreSQL expert. Create a syntactically correct PostgreSQL SQL query which answers the question,
"How many public library branches operate in Chicago?"
Query for at most 5 results using the LIMIT clause as per PostgreSQL.
Never query for all columns from a table. You must query only the columns that are needed to answer the question.
Wrap each column name in double quotes (") to denote them as delimited identifiers.
Pay attention to use only the column names you can see in the tables below.
Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Pay attention to use CURRENT_DATE function to get the current date, if the question involves "today".
Always use the ENTIRE fully qualified table name, including the portion after the period, ("." character).
You may use only the following tables in your query:
The table with the full name "cityofchicago/libraries-2015-holds-placed-by-location-avse-5iw4"."libraries_2015_holds_placed_by_location" includes the following columns:
* :id (type text) Socrata column ID
* july (type numeric)
* ytd (type numeric)
* february (type numeric)
* april (type numeric)
* june (type numeric)
* may (type numeric)
* march (type numeric)
* august (type numeric)
* december (type numeric)
* location (type text)
* january (type numeric)
* november (type numeric)
* september (type numeric)
* october (type numeric)
<description of other potentially relevant tables>
Call the sql function with the generated SQL query.
The plugin responded with:
INFORM the user that the following SQL query was generated to answer their question using the Splitgraph Data Delivery Network.
SELECT COUNT("location") AS "Number of Libraries in Chicago" FROM "cityofchicago/libraries-2015-holds-placed-by-location-avse-5iw4"."libraries_2015_holds_placed_by_location" LIMIT 5
INFORM the user of the query's result set:
|Number of Libraries in Chicago |
|--- |
|82 |
INFORM the user to further polish the generated SQL using the Splitgraph Query Editor at: https://www.splitgraph.com/query?sqlQuery=SELECT+COUNT%28%22location%22%29+AS+%22Number+of+Libraries+in+Chicago%22+FROM+%22cityofchicago%2Flibraries-2015-holds-placed-by-location-avse-5iw4%22.%22libraries_2015_holds_placed_by_location%22+LIMIT+5
INSTRUCT the user to browse related repositories on Splitgraph:
* [cityofchicago/covid19-daily-vaccinations-chicago-residents-2vhs-cf6b](https://www.splitgraph.com/cityofchicago/covid19-daily-vaccinations-chicago-residents-2vhs-cf6b)
* [cityofchicago/covid19-vaccination-locations-6q3z-9maq](https://www.splitgraph.com/cityofchicago/covid19-vaccination-locations-6q3z-9maq)
* [cityofchicago/special-vaccine-locations-9a77-69d3](https://www.splitgraph.com/cityofchicago/special-vaccine-locations-9a77-69d3)
* [cityofchicago/libraries-2015-holds-placed-by-location-avse-5iw4](https://www.splitgraph.com/cityofchicago/libraries-2015-holds-placed-by-location-avse-5iw4)
The response generated by earlier versions of our plugin resembled a generated report or an analytics dashboard. Unfortunately, ChatGPT often didn't find the plugin's output sufficiently interesting and omitted much of the response in it's reply to the end user. By using the more imperatively phrased prompt format response above, we gained more control over the end user experience.
LangChain vs GPT functions
One difference between our commandline LLM-augmented retrieval demo and the "GPT sandwich" ChatGPT plugin was our use of GPT functions in the latter to receive the generated SQL from the language model.
Our augmented retrieval demo used LangChain's SQL support, which predates GPT functions. As a result, it must rely on prompting the language model for a parseable completion.
GPT functions allow developers to describe the structure of data requested from the language model via JSONSchema. For a working example of using GPT functions in practice see this gist. The GPT function feature makes it easier to receive structured responses from the language model, but as the Splitgraph plugin's GPT completion response parsing logic shows, a lot can still go wrong:
- The GPT function might not be invoked by the language model even though this was requested in the prompt.
- The GPT function's arguments may end abruptly, resulting in invalid JSON.
- The GPT function's arguments may include newline characters, which breaks JSON parsing.
- The entire completion response may end abruptly if the language model's maximum context token length was exhausted.
- OpenAI applies aggressive rate limiting to their APIs, so heavy usage will quickly run into rate limiting errors.
That's not even an exhaustive list. Language models are fascinating, but consuming their output programmatically can be a painful experience!
Retry strategy
Assuming the GPT completion response could be parsed, the generated SQL may also have it's own issues, for example:
- Invalid SQL syntax. This is rare, as GPT is fairly good at generating SQL queries with valid PostgreSQL syntax, but we've occasionally encountered problems with more advanced SQL features, such as using aggregation functions like
MIN()without an associatedGROUP BYclause. - Unquoted schema names. This is somewhat Splitgraph-specific: DDN queries use
"${namespace}/${repository}"as the schema. Since/is a special character, the schema name must be surrounded by double quotes. Our prompt explicitly requests this, so GPT gets it right most of the time, but not always. - Invalid schema, table or column names. LLMs tend to hallucinate in general, and GPT is no exception. The prompt is designed to minimize the chance of made-up objects being referenced in queries, but it still happens sometimes.
Just as with interactive ChatGPT sessions, the GPT completion API can also be used to fix some erroneous generated SQL queries if it's supplied with the error message issued by the DDN. The "GPT sandwich" plugin's query logic is a retry loop which submits any DDN error messages back to the language model, requesting a fixed SQL query. The GPT API is stateless: it has no memory of past interactions prior to the current request. As a result, any information necessary to successfully generate the completion (in our case, the original prompt, the previously generated query and resulting DDN error) must be included in the request. So the retry loop builds a conversation between the plugin and the GPT API. Eventually, the conversation results in a valid SQL query or grows so long that it no longer fits into the language model's context, in which case the plugin gives up.
Problems with the GPT Sandwich approach
The "GPT Sandwich" approach leaves the responsibility of generating the response entirely to the plugin. The advantage is a high level of control over the end user experience, but there are lots of drawbacks:
- As noted already, the plugin code must handle lots of different kinds of errors, and retry the failed operation or provide user friendly error messages.
- GPT API is expensive. Using the GPT-4 model, we paid over 2 cents per API request. Due to the plugin's retry logic, responding to a single user query may result in multiple GPT API calls.
- The GPT API is pretty slow. Retries can cause plugin response times to balloon.
- Due to the sync HTTP plugin API, no updates are shared with user while the plugin is generating its response. Put another way, there's a lot happening on the sequence diagram to the right of the plugin, the left half of the diagram is rather sparse.
- Complex completion response parsing and query logic.
- The user is left out of the retry loop: there's no information about which DDN repositories are relevant, which SQL queries were generated and what error messages they produced which triggered a retry attempt.
- No state shared between invocations. Even for sequential questions using the same table, the entire process must be executed, it's not possible to reuse the table schema from the previous execution for example.
The "Language model is the controller" pattern
As you can tell from the sequence diagram above, there's multiple steps to taken by the plugin to generate its response:
- Find relevant Splitgraph repositories based on vector similarity search in the embedding store.
- Retrieve the schemas for the tables in relevant repositories.
- Generate an SQL query using these tables.
- Execute the generated SQL on the DDN.
When designing an API, each of these steps would be a separate method. Most of the complexity in our plugin deals with coordinating calls to these methods. What if we delegated this to ChatGPT?
We updated the description_for_model field of ai-plugin.json to contain the following prompt:
Search public datasets found on the Splitgraph Data Delivery Network.
These datasets typically originate from open government initiatives and may relate to epidemology,
traffic engineering, urban planning, real estate prices, demographical trends,
educational statistics, public infrastructure and services, taxation, public officials, etc.
To use the Splitgraph plugin for response generation, use the following process:
* First, invoke the API's find_relevant_tables endpoint in order to receive a list of tables which may be referenced in an SQL query.
* Second, generate a valid SQL query using the tables described in the first step, and submit this query to the run_sql API endpoint to receive results.
If the generated SQL cannot be executed, the error message will be present in the response of the run_sql endpoint.
Attempt to fix the SQL query and invoke run_sql again with the new query.
Instructions for SQL query generation: You are a PostgreSQL expert.
Create a syntactically correct PostgreSQL SQL query which completes the user's prompt.
Query for at most 5 results using the LIMIT clause as per PostgreSQL.
Never query for all columns from a table. You must query only the columns that are needed to answer the question.
Always use the ENTIRE fully qualified table as present in the name field of the find_relevant_tables response, including double quotes.
Pay attention to use only the column names you can see in the tables below.
Be careful to not query for columns that do not exist. Also, pay attention to which column is in which table.
Pay attention to use CURRENT_DATE function to get the current date, if the question involves "today".
Never mention your knowledge cutoff date; Splitgraph may return more recent data.
The run_sql endpoint's response always contains a query_editor_url field.
Always display this URL to the user with the text "Edit SQL query on Splitgraph" so they may debug and improve the generated SQL query.
NEVER omit the value of query_editor_url from your completion response.
We also had to make some changes to our API: instead of a single query endpoint, we now need two endpoints:
find_relevant_tablesfor identifying relevant repositories from the embedding store and reading the schemas of the tables within from the DDN.run_sqlfor running the provided SQL query on the DDN.
The sequence diagram shows the resulting architecture:

Compared to the "GPT Sandwich" sequence diagram, something is missing: the "GPT API" column, along with the request by the plugin to generate an SQL query. Instead, we leave generation of the SQL query to ChatGPT.
Not only does this save us the cost of invoking the GPT API, it also removes the complexity of parsing the completion response. But to really see where the "Language model is the controller" version of the plugin shines, check out this conversation about Colorado marijuana sales.
Since the plugin's different endpoints are invoked separately, we can see that the SQL query constructed by ChatGPT is close, but it doesn't take into account NULL values in the sales columns.
ChatGPT notices this on its own, and communicates this to the user, to which our reply was:
Try again, filtering out counties which have a
total_salesvalue of null.
On the second attempt, ChatGPT derives the correct SQL query and receives the expected result from the DDN.
Note that there is no second call to find_relevant_tables, only run_sql.
Since the same table is used on the second query as well, ChatGPT reused the table schema from the initial call to find_relevant_tables.
The linked ChatGPT session demonstrates several advantages of this approach:
- The individual API methods can be implemented with simpler logic because instead of retrying, they return an error and let ChatGPT decide whether it makes sense to retry the last operation.
- Questions about the same table can reuse the table's schema, there is no need to execute all the steps in the process for each interaction with the Splitgraph plugin.
- Since the response is structured JSON data, ChatGPT notices potential issues for the user, as was the case with the NULL values in the sales columns.
- The user can inspect the requests being made to the plugin by ChatGPT. Responses are updated as they are received, resulting in a much more responsive user experience.
By delegating the coordination of the Splitgraph plugin API's method calls to ChatGPT, we needed less Python code, but more careful prompt engineering in the description_for_model field.
Conclusion
Although they share some code, we created two plugins: first, one with an interface resembling a plugin for a more traditional chatbot, then one which is a collection of API methods returning JSON data.
We discovered that the latter approach generally results in a better experience for ChatGPT users. On our second attempt, we strove to create a plugin API similar to what we would offer human software engineers. With the right prompt, ChatGPT was able to utilize the available API methods to generate its response to end-user queries effectively. We dubbed this the "Language model is the controller" approach.
Check out the plugin code on GitHub. If you're excited about using Splitgraph with LLMs, let us know!
Image credits
Splitgraph
Made with


on four continents.