Splitgraph has been acquired by EDB! Read the blog post.
Rust visitor pattern and efficient DataFusion query federation
We explore the inner workings of DataFusion filter pushdown optimisation, and see what it takes to ship them to remote data sources.
We've recently released a new feature in Seafowl, allowing one to remotely query a variety of external data sources. Coincidentally,
the feature is completely independent of Seafowl itself; anyone using DataFusion as a query engine framework can make use of it.
In fact, to facilitate this, we've factored out the code to a stand-alone crate named datafusion-remote-tables!
In this blog post we'll touch on how this querying mechanism works. Specifically, we'll focus on how we achieve filter pushdown, a special optimisation reducing the amount of data needed to be transferred over the network. As it happens, this also serves as a great overview of some DataFusion internals as well as a couple of fundamental Rust concepts1 at the same time.
DataFusion tables and filter expressions 101
In order for a particular data source to become queryable in DataFusion, it needs to implement the
TableProvider trait.
It is an async_trait, so as to enable an asynchronous scan method, which is responsible for creating a physical plan
for a particular query.
The scan method receives a number of useful parameters:
projection: An optional list of column indices. If provided scopes down the required output to only a subset of table's columns.filters: A slice ofExprs (see below) parsed from theWHEREclause.limit: Denotes the maximum number of rows requested (LIMITclause).
All of these represent an optimisation strategy for pruning the data closer to where it actually lives. In our remote table implementation of this trait we use all these arguments to re-construct a SQL query in a string form native to the corresponding remote data source and execute it2.
Importantly, an Expr is a DataFusion enum representing an arbitrary logical expression (and thus filters as well):
#[derive(Clone, PartialEq, Eq, Hash)]
pub enum Expr {
...
/// A named reference to a qualified field in a schema.
Column(Column),
/// A constant value.
Literal(ScalarValue),
/// A binary expression such as "age > 21"
BinaryExpr(BinaryExpr),
...
}
It is also recursive, as some of the variants contain structs that are themselves composed out of Expr:
#[derive(Clone, PartialEq, Eq, Hash)]
pub struct BinaryExpr {
/// Left-hand side of the expression
pub left: Box<Expr>,
/// The comparison operator
pub op: Operator,
/// Right-hand side of the expression
pub right: Box<Expr>,
}
while others (e.g. Column and ScalarValue) represent leaf nodes in the expression tree.
supports_filter_pushdown method
Just because WHERE and LIMIT clauses are used in a statement, doesn't mean they'll be passed as arguments to the
scan function. This is ultimately controlled by another method in the TableProvider trait named supports_filter_pushdown.
During plan optimisation phase, DataFusion splits the whole WHERE clause into constituent Exprs separated by ANDs.
Then it calls supports_filter_pushdown method for each Expr to find out the corresponding pushdown status:
Unsupported: The filter node is kept in the plan, and it won't be passed down intoscan. DataFusion will perform filtering once all the matching rows are fetched. This is the default pushdown status.Inexact: The filter node is kept in the plan, but it is also passed down intoscan. The data source will try to filter as much data as it can, but it doesn't guarantee that all rows pass the provided filter3.Exact: The filter node is removed from the plan and is passed down intoscan. The data source guarantees that all returned rows match the filter.
The reason why the WHERE clause is broken up at the ANDs is for enabling granular pushdown: all individual conjunction
components that are shippable can be pushed down independently of each other's pushdown status. This allows for reaping the
performance benefits even when only a part of the whole WHERE clause is shippable, while retaining correctness.
FDW approach
Note that projection is said to be commutative with filters, meaning the order of their application (source vs destination) is not important
(i.e. one trims down the columns, while the other trims down the rows returned). The implication of this is that projection
always gets pushed down to scan, regardless of the filter pushdown status.
However, limit is not commutative with filters, as both prune rows according to different rules. Hence, limit is passed
down to scan if and only if all filter expressions in a query are eligible for exact pushdown. Keep in mind that the potential reduction
in the amount of data retrieved with these two parameters is anywhere between 0 and 100%, so the performance benefits
can be very large.
Therefore, in order to make the most out of it, it pays off to be as diligent as possible in supports_filter_pushdown.
We need to ensure that we can determine the shippability of each (part of each) expression in a query, and when needed
translate it to the dialect of the remote data source.
This problem has already been encountered in the family of Postgres foreign data wrappers (FDWs). The usual approach there is to recursively walk the AST of the query, converting it piece-by-piece into remote-compatible SQL if possible, otherwise forego the filter pushdown.
Traversing a DataFusion's Expr
Fortunately, DataFusion provides the primitives that suit our needs in the form of
ExpressionVisitor trait.
It employs the visitor pattern for walking the entire tree of an arbitrary Expr in a post-order manner. In particular,
it provides two convenient methods for hooking custom actions. One is invoked just prior to visiting all the
children of a given node (pre_visit), while the other is invoked once all the child nodes have been visited (post_visit).
Consider the following illustrative example:
SELECT ... WHERE c_1 ^ 21 > c_2 OR c_3 = 'abc'
The entire filter expression and the node visit order looks like below
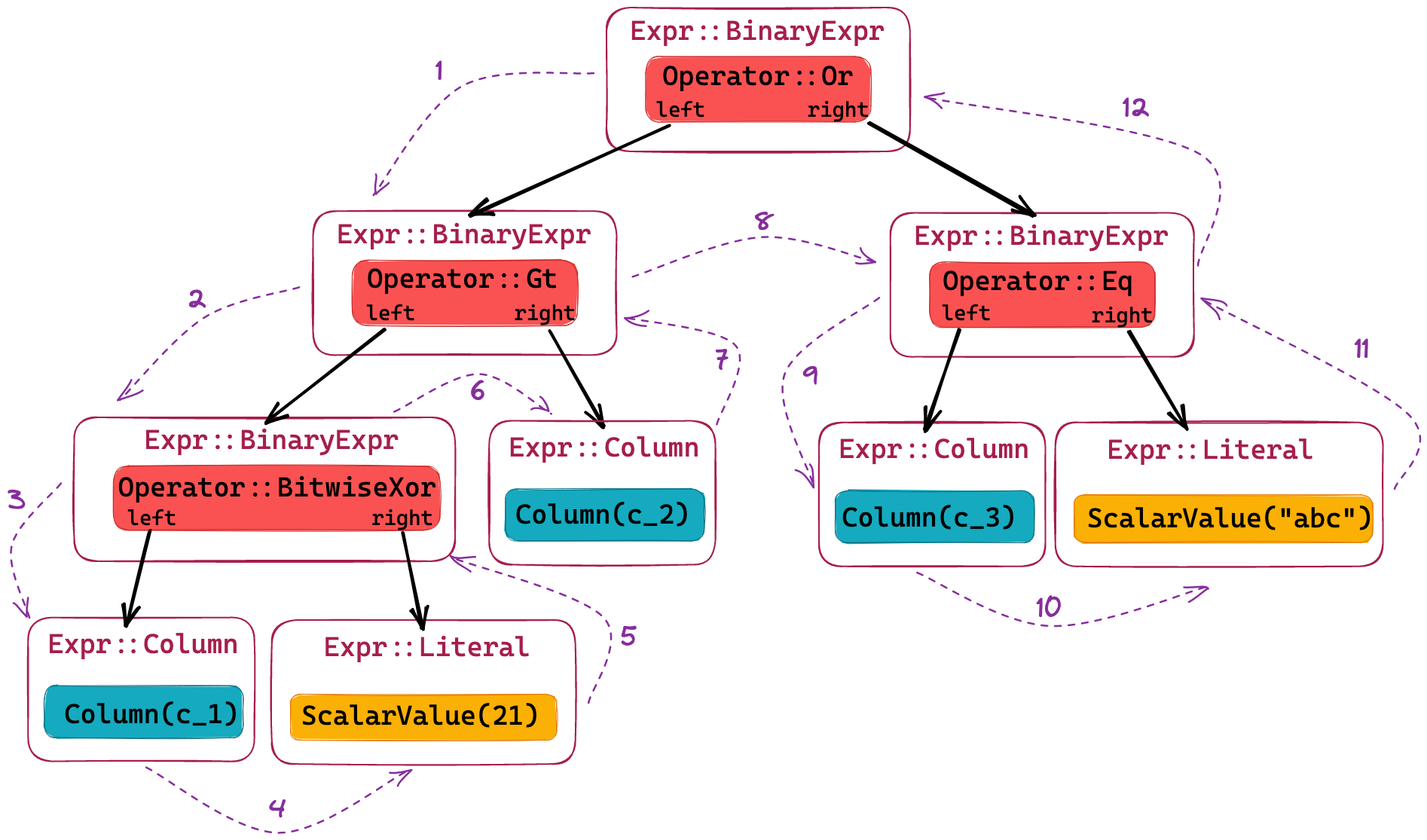
This should now clarify how we can utilise the two hooks in ExpressionVisitor trait for our purpose. On the one hand,
we can check for the shippability of the expression, operator or data type of the current node in the pre_visit method.
If it's not compatible with the remote there's no need to waste time visiting any of the children, so we can exit the
visit immediately and inform DataFusion about this (i.e. flag the filter pushdown as Unsupported in supports_filter_pushdown).
On the other hand, if we do reach the post_visit method on a particular node it means that it (alongside all its children
nodes) is shippable. In other words, there is a corresponding remote-compatible SQL string (and we should flag the
filter pushdown as Exact in supports_filter_pushdown). Furthermore, this enables a bottom-up approach of generating
the equivalent SQL efficiently.
Namely, we can't generate the SQL representation for a recursive node (in our case Expr::BinaryExprs) before knowing
the SQL of its components. Therefore, we must first reach the leaf nodes (Expr::Column and Expr::Literal), which
can be independently converted to SQL, and then progressively build the SQL up from there.
An ideal way to facilitate this is to use a stack. Simply push resulting SQL for each expression to the stack, and for any interpolation
(recursive nodes) use the SQL from child nodes (i.e. pop from the stack). By the time we exit from post_visit of a root node, we will
have a single element on the stack, representing the SQL of the entire expression.
Filter translation
Prior to implementing the ExpressionVisitor, we need to keep in mind one more requirement for our filter pushdown
mechanism, and that is re-usable polymorphism. In other words, we want to have the same interface regardless of the remote source
type, and re-use as much of it as possible. For start we aim to support PostgreSQL (whose dialect DataFusion is closest to),
as well as MySQL and SQLite.
To achieve this let's first make a new trait, one that converts a leaf node or an operator to SQL for a particular data source:
pub trait FilterPushdownConverter {
fn col_to_sql(&self, col: &Column) -> String {
quote_identifier_double_quotes(&col.name)
}
fn scalar_value_to_sql(&self, value: &ScalarValue) -> Option<String> {
match value {
ScalarValue::Utf8(Some(val)) | ScalarValue::LargeUtf8(Some(val)) => {
Some(format!("'{}'", val.replace('\'', "''")))
}
_ => Some(format!("{}", value)),
}
}
fn op_to_sql(&self, op: &Operator) -> Option<String> {
Some(op.to_string())
}
}
pub fn quote_identifier_double_quotes(name: &str) -> String {
format!("\"{}\"", name.replace('\"', "\"\""))
}
Here we make sure to quote the identifier used in the column expression to handle any special characters properly (such as spaces).
In addition, we enclose the string literals in single quotes, as well as convert the Operator enum to the default string representation (relying on the Display trait).
The default trait implementation is perfectly adequate for Postgres:
pub struct PostgresFilterPushdown {}
impl FilterPushdownConverter for PostgresFilterPushdown {}
However, the other two data sources require some changes. For instance, MySQL uses backticks to escape the identifiers,
while the bitwise xor operator is denoted as ^ (and not # as in Postgres, which op.to_string() returns):
pub struct MySQLFilterPushdown {}
impl FilterPushdownConverter for MySQLFilterPushdown {
fn col_to_sql(&self, col: &Column) -> String {
quote_identifier_backticks(&col.name)
}
fn op_to_sql(&self, op: &Operator) -> Option<String> {
match op {
Operator::BitwiseXor => Some("^".to_string()),
_ => Some(op.to_string()),
}
}
}
pub fn quote_identifier_backticks(name: &str) -> String {
format!("`{}`", name.replace('`', "``"))
}
On the other hand, SQLite doesn't have a dedicated bitwise xor operator4:
pub struct SQLiteFilterPushdown {}
impl FilterPushdownConverter for SQLiteFilterPushdown {
fn op_to_sql(&self, op: &Operator) -> Option<String> {
match op {
Operator::BitwiseXor => None,
_ => Some(op.to_string()),
}
}
}
The winning pushdown
Now, in order to actually employ our filter conversion we need to implement the DataFusion's ExpressionVisitor. Note
that the Rust's usual orphan rules apply here: when implementing a trait for some type at least one of them needs to
be defined locally (in the current crate). In our case however we go one step ahead, as we want to implement the
ExpressionVisitor trait for any type that also implements the FilterPushdownConverter trait. This would ensure
that a single implementation covers all remote types (Postgres, MySQL, SQLite).
The naive way to go about this is to try the following definition:
impl<T: FilterPushdownConverter> ExpressionVisitor for T {
...
However, rustc will quickly dissuade you from this approach, as this can also lead to violating the orphan rule:
error[E0210]: type parameter `T` must be used as the type parameter for some local type (e.g., `MyStruct<T>`)
--> datafusion_remote_tables/src/filter_pushdown.rs:110:6
|
110 | impl<T: FilterPushdownConverter> ExpressionVisitor for T {
| ^ type parameter `T` must be used as the type parameter for some local type
|
= note: implementing a foreign trait is only possible if at least one of the types for which it is implemented is local
= note: only traits defined in the current crate can be implemented for a type parameter
For more information about this error, try `rustc --explain E0210`.
In other words, you could inadvertently implement FilterPushdownConverter for some foreign type that already implements
ExpressionVisitor, at which point there would be a conflict. Thankfully, the error message is very helpful and suggests
the proper course of action. Namely, we must use a local struct in the definition instead. This works well with our intention
of keeping a stack of converted SQL expression during the visit:
pub struct FilterPushdownVisitor<T: FilterPushdownConverter> {
pub source: T,
// LIFO stack for keeping the intermediate SQL expression results to be used in interpolation
// of the parent nodes. After a successful visit, it should contain exactly one element, which
// represents the complete SQL statement corresponding to the given expression.
pub sql_exprs: Vec<String>,
}
impl<T: FilterPushdownConverter> FilterPushdownVisitor<T> {
// Intended to be used in the node post-visit phase, ensuring that SQL representation of inner
// nodes is on the stack.
fn pop_sql_expr(&mut self) -> String {
self.sql_exprs
.pop()
.expect("No SQL expression in the stack")
}
}
Finally, we can go ahead and implement the two visitor methods:
impl<T: FilterPushdownConverter> ExpressionVisitor for FilterPushdownVisitor<T> {
fn pre_visit(self, expr: &Expr) -> Result<Recursion<Self>> {
match expr {
Expr::Column(_) => {}
Expr::Literal(val) => {
if self.source.scalar_value_to_sql(val).is_none() {
return Err(DataFusionError::Execution(format!(
"ScalarValue {} not shippable",
val,
)));
}
}
Expr::BinaryExpr(BinaryExpr { op, .. }) => {
// Check if operator pushdown supported; left and right expressions will be checked
// through further recursion.
if self.source.op_to_sql(op).is_none() {
return Err(DataFusionError::Execution(format!(
"Operator {} not shippable",
op,
)));
}
}
_ => {
// Expression is not supported, no need to visit any remaining child or parent nodes
return Err(DataFusionError::Execution(format!(
"Expression {:?} not shippable",
expr,
)));
}
};
Ok(Recursion::Continue(self))
}
...
Nothing fancy here, all we use the pre_visit method for is to bail out of the whole visit as soon as we detect a node
that is not shippable. The meat of the implementation is in the post_visit method:
...
fn post_visit(mut self, expr: &Expr) -> Result<Self> {
match expr {
// Column and Literal are the only two leaf nodes atm - they don't depend on any SQL
// expression being on the stack.
Expr::Column(col) => self.sql_exprs.push(self.source.col_to_sql(col)),
Expr::Literal(val) => {
let sql_val = self.source.scalar_value_to_sql(val).unwrap();
self.sql_exprs.push(sql_val)
}
Expr::BinaryExpr(BinaryExpr { op, .. }) => {
// The visitor has been through left and right sides in that order, so the topmost
// item on the SQL expression stack is the right expression
let right_sql = self.pop_sql_expr();
let left_sql = self.pop_sql_expr();
let op_sql = self.source.op_to_sql(&op).unwrap();
self.sql_exprs
.push(format!("{} {} {}", left_sql, op_sql, right_sql))
}
_ => {}
};
Ok(self)
}
}
Again, the leaf nodes are simply converted to the equivalent SQL using our FilterPushdownConverter trait and pushed
to the stack. As for the binary expression, we first pop two items from the stack, corresponding to right and left
sub-expression SQL, and then interpolate them with the operator. In principle, since the Expr has an implicit operator precedence,
we need to convert it to an explicit one using parenthesis if the left/right sub-expression is also a BinaryExpr of
lower operator precedence, but we omit that here for the sake of brevity.
Putting it all together
Lastly, in order to make the full trip from a Expr to a SQL string we can define a generic helper function, where we set off
a visit starting at the root expression, and then extract the final SQL representation:
pub fn filter_expr_to_sql<T: FilterPushdownConverter>(
filter: &Expr,
source: T,
) -> Result<String> {
// Construct the initial visitor state
let visitor = FilterPushdownVisitor {
source,
sql_exprs: vec![],
};
// Perform the walk through the expr AST trying to construct the equivalent SQL for the
// particular source type at hand.
let FilterPushdownVisitor { sql_exprs, .. } = filter.accept(visitor)?;
Ok(sql_exprs
.first()
.expect("Exactly 1 SQL expression expected")
.clone())
}
For our example expression from above, the resulting PostgreSQL statement is:
SELECT ... WHERE "c_1" # 21 > "c_2" OR "c_3" = 'abc'
while the MySQL output is:
SELECT ... WHERE `c_1` ^ 21 > `c_2` OR `c_3` = 'abc'
As for SQLite, an error gets thrown since the conversion of the bitwise xor operator is not supported. As mentioned, in such
cases a bare SELECT without the WHERE clause would get pushed down, while the desired filtration is then achieved afterwards.
Had there been an AND instead of an OR in our query however, DataFusion would have broken the WHERE clause into two expressions,
and the second one ("c_3" = 'abc') would have been pushed down.
Conclusion
We hope this exploratory blog post has intrigued you enough to dig into the DataFusion framework (and perhaps Seafowl too).
On our side, we aim to keep expanding the surface area of shippable filter expressions as well as supported remotes
in the datafusion-remote-tables crate, so if you're already using DataFusion you may find it handy.
- And so can be helpful to someone new to DataFusion and/or Rust, like the author of this blog post.↩
- For actually running the query on the remote we use the connector-x crate.↩
- This is what ordinary Seafowl tables use, as it allows us to perform partition pruning.↩
- Given that it can be emulated by other primitive boolean operators easily.↩
Splitgraph
Made with


on four continents.