Splitgraph has been acquired by EDB! Read the blog post.
Airbyte, dbt, Splitgraph: how we built our modern data stack
We talk about our modernized data stack that uses Airbyte for data ingestion, dbt for transformations and Splitgraph itself for storage, versioning, discoverability and querying.
Note (February 2022): For a deeper dive on how our dbt integration works and how you can run dbt models on Splitgraph Cloud, check out a newer blog post here!
Introduction
Some time ago, we wrote about how we use the Splitgraph engine for our own business analytics. Soon, Splitgraph evolved into a cloud offering and we built more integrations for it. Eventually, we created a private instance of Splitgraph to use for our own data stack.
In this post, we'll talk about how we use Airbyte, dbt and Splitgraph for our analytics needs. We'll also touch on our thoughts on Splitgraph's place in the modern data stack as a simple discoverability, storage and orchestration layer.
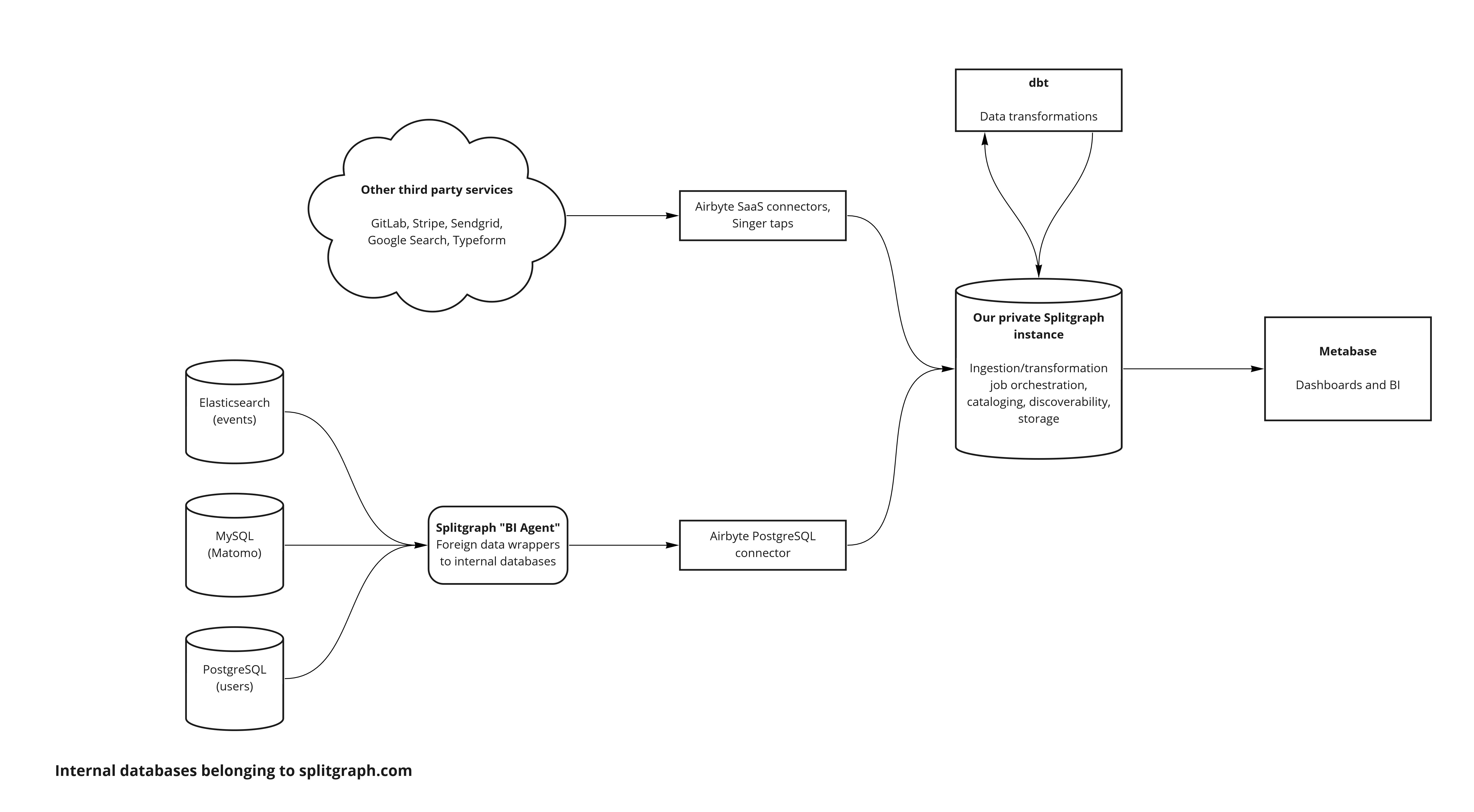
Splitgraph "BI agent": punching through the firewall
In our previous post, we used a single Splitgraph engine for our analytics data and as a Metabase application database. It still exists, but we downgraded it to the role of a "BI agent".
The "agent" is a PostgreSQL instance with foreign data wrappers. These proxy to tables in MySQL (Matomo), Elasticsearch (event data) and our production PostgreSQL database (other data). The "agent" acts as a SQL firewall to avoid exposing all splitgraph.com services to the outside world while still letting us export necessary data for analytics.
Loading data: Airbyte
Airbyte is a new standard for data integrations that extends on Singer (more on the specification here). Like Singer, it defines sources (taps) and destinations (sinks). The two components communicate by emitting or receiving messages in a standardized format:
- Sources load data from SaaS vendors or databases and output it to the standard output as a stream of JSON messages
- Destinations consume a stream of JSON messages and write it out to a database or a data warehouse
However, Airbyte also has two important improvements on Singer.
Airbyte connectors specify a JSONSchema for their configuration. Singer taps
would make the user dig around the documentation for each individual tap. With
Airbyte, one can run a connector with the spec argument to find out what
parameters it requires.
All connectors ship as Docker images. This means that there are no extra dependencies to running them apart from Docker. Compare this with Singer, where each tap or target requires a separate Python virtual environment to avoid conflicts.
Our usage of Airbyte
Instead of using the Airbyte web application, we run the Airbyte connectors directly with Splitgraph. More on that later.
By default, Airbyte destinations store data they receive from connectors as a table of raw JSON messages. This is how we store data from the "BI agent": we use Airbyte's PostgreSQL connector to replicate the Matomo, Elasticsearch and PostgreSQL data. Airbyte doesn't do anything else with that data, since we do further processing on it anyway.
Airbyte also supports best-effort "basic normalization". This automatically generates a dbt model from every stream, converting it into a set of normalized tables. For example, it will unpack a nested JSON object into two separate tables. We use this basic normalization for other SaaS services like Sendgrid, Stripe, GitLab etc.
Modelling: dbt
dbt is a modelling tool that lets analysts store their data models in version control and build composable transformations from small SQL snippets. It was a natural replacement for our ad hoc SQL scripts that we used to run on our "BI agent".
We used Airbyte's default dbt model generator from their basic normalization as the first step ("staging" in dbt terminology). This would unpack the data we loaded from PostgreSQL as raw JSON into actual tables. Then, we rewrote our SQL code into separate dbt model files that reference each other.
An example of a dbt model that runs on Splitgraph Cloud is
here. This
repository also has a splitgraph.yml Splitgraph Cloud project file in it.
This file lets us store our whole data stack, including the data source
definitions, dbt models and the catalog metadata, in a single version-controlled
repository.
We're currently working on a generator for these project files.
Storage, orchestration and discovery: Splitgraph
Our dogfooding private Splitgraph instance (which we unimaginatively named Eukanuba) has multiple purposes and ties our data stack together.
Data warehouse
Splitgraph acts as our data warehouse. Each dataset, whether it's a raw Airbyte table or a transformed dbt model, becomes a repository on Splitgraph. Because Splitgraph uses columnar storage, the datasets take less space than they would in a PostgreSQL database. In addition, analytical queries against this data are faster.
We also store old versions of our dbt models, since we load each dbt result into a separate Splitgraph image. This lets us easily compare the output of dbt across points in time. For example, this query looks at our blog post performance changes between two different dates:
SELECT
old.post_id,
old."Total visits" AS old_visits,
new."Total visits" AS new_visits
FROM
"analytics/splitgraph-com:latest".blog_post_performance new
JOIN
"analytics/splitgraph-com:20211120".blog_post_performance old
USING(post_id);
Orchestration
Splitgraph runs the Airbyte connectors and dbt models for us. We wrote a couple of wrappers around Airbyte and dbt, turning them into "data source" plugins. Because Splitgraph is based on PostgreSQL, it was straightforward to do so.
For Airbyte, we connect an arbitrary source to the PostgreSQL destination,
pointing it to the Splitgraph engine. When the ingestion finishes, Splitgraph
runs the equivalent of sgr commit, snapshotting the dataset and making it
available on the instance.
For dbt, the plugin expects a "map" of dbt sources to Splitgraph repositories. At runtime, Splitgraph "mounts" required source datasets and repoints the dbt projects to them. After dbt builds the model, we similarly snapshot the dataset.
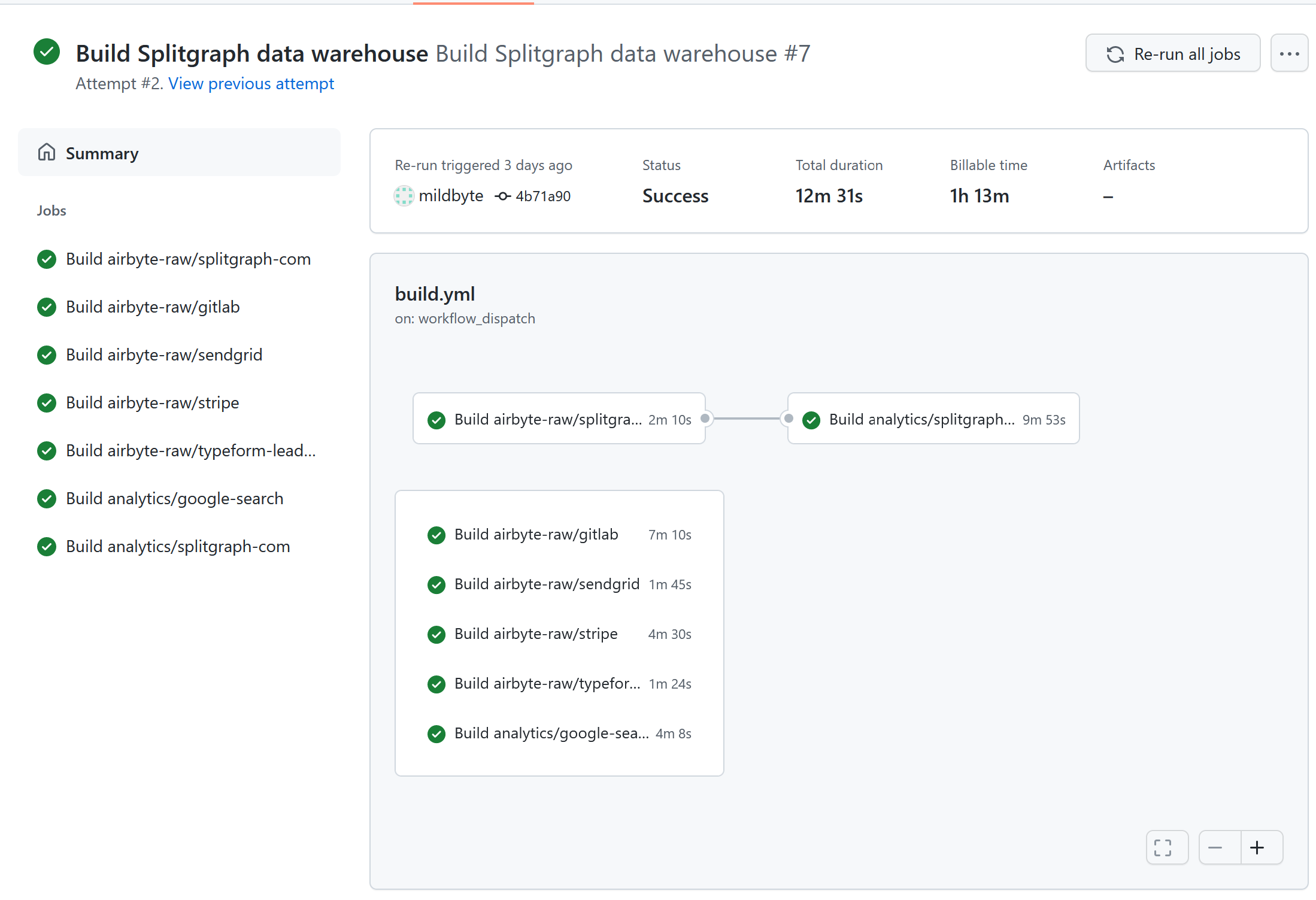
To start these data loads and transformations, Splitgraph has a scheduler. Recently, we've been experimenting with using GitHub Actions to trigger jobs. An example of using dbt and Splitgraph to run data transformations with GitHub actions is on our GitHub.
Data catalog
Finally, Splitgraph is our data catalog. We give each dataset relevant topics, for example, tagging them by source, by provider (Airbyte, dbt) or by normalization type. We also attach metadata to datasets, like the name of the dbt model they correspond to.
In addition, Splitgraph supports "live" plugins that allow querying the data at source. One of our customers uses this functionality to maintain a catalog of CSV files in their S3 data lake.
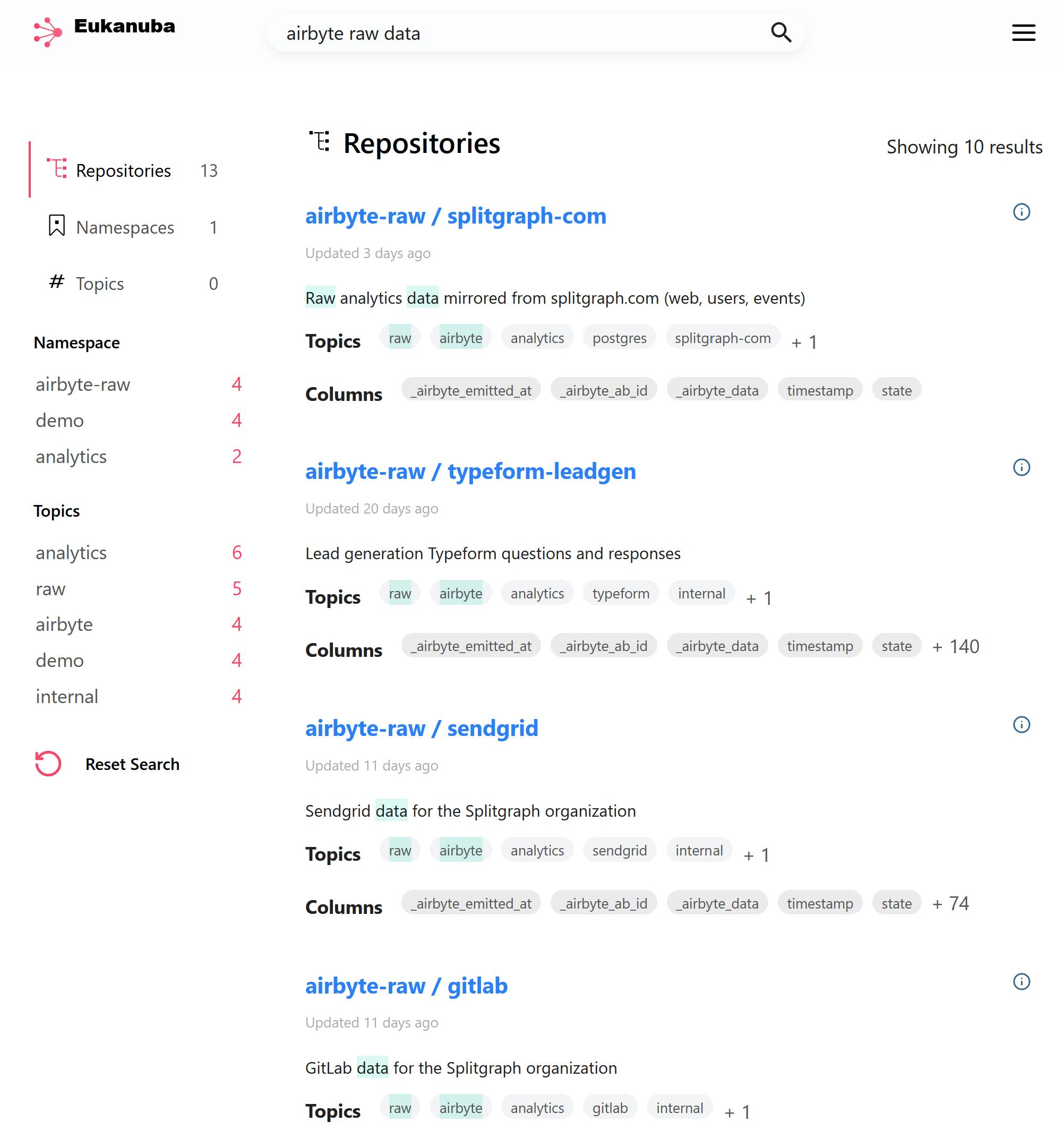
In the future, we are planning to extend our dbt integration to also import the dbt documentation website. This will let us, and other Splitgraph users, to view their data documentation, explore data lineage and immediately query the data. With live plugins, they'll also be able to point Splitgraph to the dbt models in their warehouse without needing to use Splitgraph for storage.
BI: Metabase
Metabase is the part of our data stack that has stayed constant. It's still an amazing tool for exploratory data analysis and dashboard building and we spoke a lot about it in the previous post. The only change we made to the setup was that now it's connected to our Splitgraph Cloud instance's PostgreSQL-compatible query endpoint.
Conclusion
In this post, we talked about how we upgraded our analytics setup to a "modern data stack" that uses Airbyte, dbt and Splitgraph.
On our GitHub, you can find the sample Splitgraph Cloud project that uses dbt to build a dataset from another dataset on Splitgraph. This repository has a GitHub Actions job and more clarification.
You can run the ingestion job against splitgraph.com, loading data into private repositories.
In a newer blog post, you will be able to find a more complex example analytics project that we ourselves use to build our data warehouse.
If you're interested in a dedicated setup of Splitgraph Cloud for your business, feel free to get in touch and join our private beta!
Splitgraph
Made with


on four continents.