Splitgraph has been acquired by EDB! Read the blog post.
Scheduling, versioning and cataloging: introducing our dbt integration
We showcase the ability to run dbt models on Splitgraph, triggering them on a schedule as well as using GitHub Actions. We also talk about how it works and share more plans for our dbt integration.
Introduction
In a previous blog post, we talked about our own data stack that uses dbt and Airbyte to build our data warehouse.
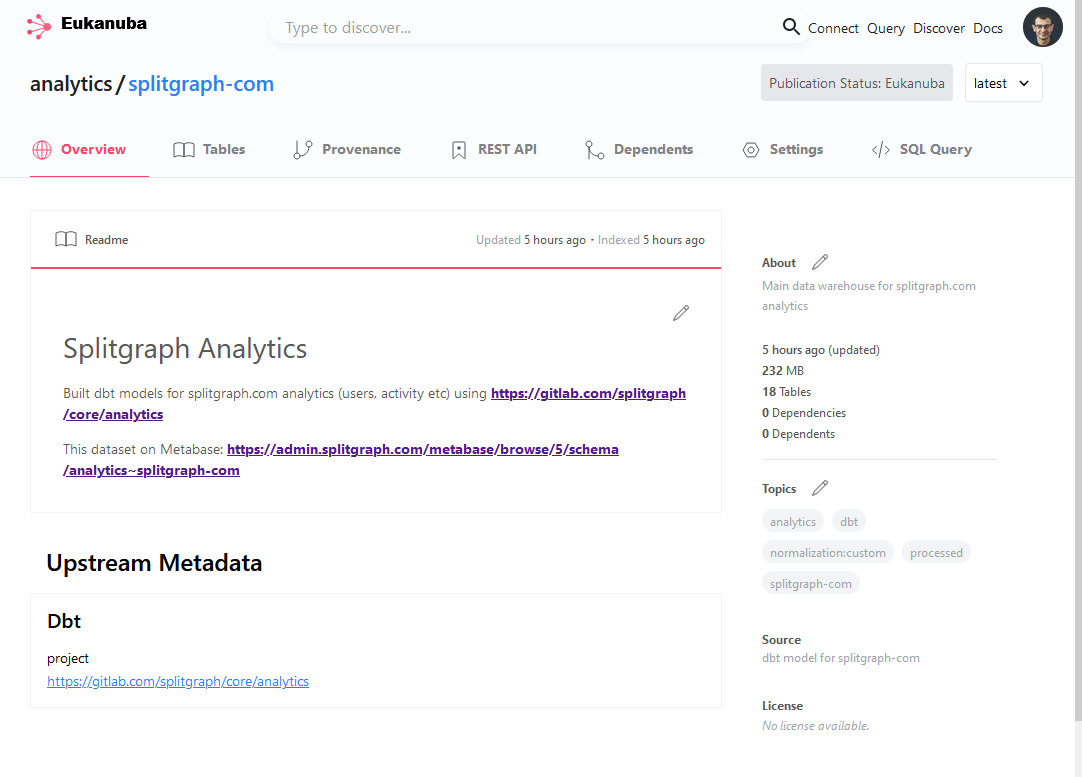 Our main analytics dataset, built with dbt on our private instance of Splitgraph Cloud.
Our main analytics dataset, built with dbt on our private instance of Splitgraph Cloud.
Today, we will show you how you can add your own dbt project to Splitgraph Cloud to build Splitgraph images with dbt models. We'll also discuss how the dbt transformation functionality works.
Don't have much time? Our GitHub has a forkable self-contained example that uses a GitHub Action to build a dataset of top commodity exporters in each country. Feel free to check it out!
Using the splitgraph.yml file
splitgraph.yml is a declarative way to define the datasets to add to Splitgraph. You can think of it as a Terraform template for your data stack. See more information in the documentation here.
We are also working on a UI to add data to Splitgraph. It will let you ingest data from over 100 SaaS sources (powered by Airbyte and Singer). It will also support data federation for popular databases and warehouses (powered by PostgreSQL Foreign Data Wrappers).
This is what the part of our splitgraph.yml file responsible for the dbt transformation looks like:
credentials:
splitgraph_dbt:
plugin: dbt
data:
git_url: https://[USERNAME]:[PASSWORD]@gitlab.com/splitgraph/core/analytics.git
repositories:
# Data transformed with dbt
- namespace: analytics
repository: splitgraph-com
external:
credential: splitgraph_dbt
plugin: dbt
is_live: false
schedule:
enabled: true
# NOTE: we currently don't support inter-task dependencies,
# so we run this 10 minutes after the main raw data update
# starts
schedule: 10 */6 * * *
params:
sources:
- dbt_source_name: airbyte_raw
namespace: airbyte-raw
repository: splitgraph-com
- dbt_source_name: stopforumspam
namespace: analytics
repository: stopforumspam
# This lets us select specific dbt models to build in this image
tables:
daily_summary:
options: { }
schema: [ ]
dim_users:
options: { }
schema: [ ]
fct_export_jobs:
options: { }
schema: [ ]
fct_ingestion_jobs:
options: { }
schema: [ ]
# ...
metadata:
topics:
- analytics
- splitgraph-com
- processed
- normalization:custom
- dbt
sources:
- anchor: dbt model for splitgraph-com
href: https://gitlab.com/splitgraph/core/analytics
description: Main data warehouse for splitgraph.com analytics
readme:
text: |
# Splitgraph Analytics
Built dbt models for splitgraph.com analytics (users, activity etc)
using https://gitlab.com/splitgraph/core/analytics
This dataset on Metabase: https://admin.splitgraph.com/metabase/browse/5/schema/analytics~splitgraph-com
extra_metadata:
dbt:
project: https://gitlab.com/splitgraph/core/analytics
This snippet:
- uses the raw data we ingest into the
airbyte-raw/splitgraph-comrepository with Airbyte. It's also in this file but has been omitted. - uses the data in the
analytics/stopforumspamrepository (available here) - builds a dbt model with statistics on active users and feature usage. It does that by joining the two datasets to exclude activity from users with known spam e-mails.
Running the file
There are two ways you can run a dbt model on Splitgraph Cloud.
The first method is using the schedule stanza. This lets you specify a cron-like syntax for Splitgraph to run the model on schedule. Note that currently we don't support inter-task dependencies. For us, this means we have to give the source airbyte-raw/splitgraph-com dataset some time to load and start the dbt model later.
To do that, use the sgr cloud load command to upload the splitgraph.yml file to Splitgraph Cloud.
The second method is by triggering the job from GitHub Actions. Our GitHub example runs the ingestion this way by executing sgr cloud sync. This lets you control when the job starts as well as manage inter-task dependencies. You can find the full GitHub Action code here.
Result
In either case, you will end up with a repository of images built from the dbt model. One benefit of using Splitgraph for this is that this repository is versioned. This means you can easily switch back to the old versions of the dataset.
You can also query the dataset on the Splitgraph DDN with any SQL client. You can even run JOINs between different versions of the dataset to see how it evolved.
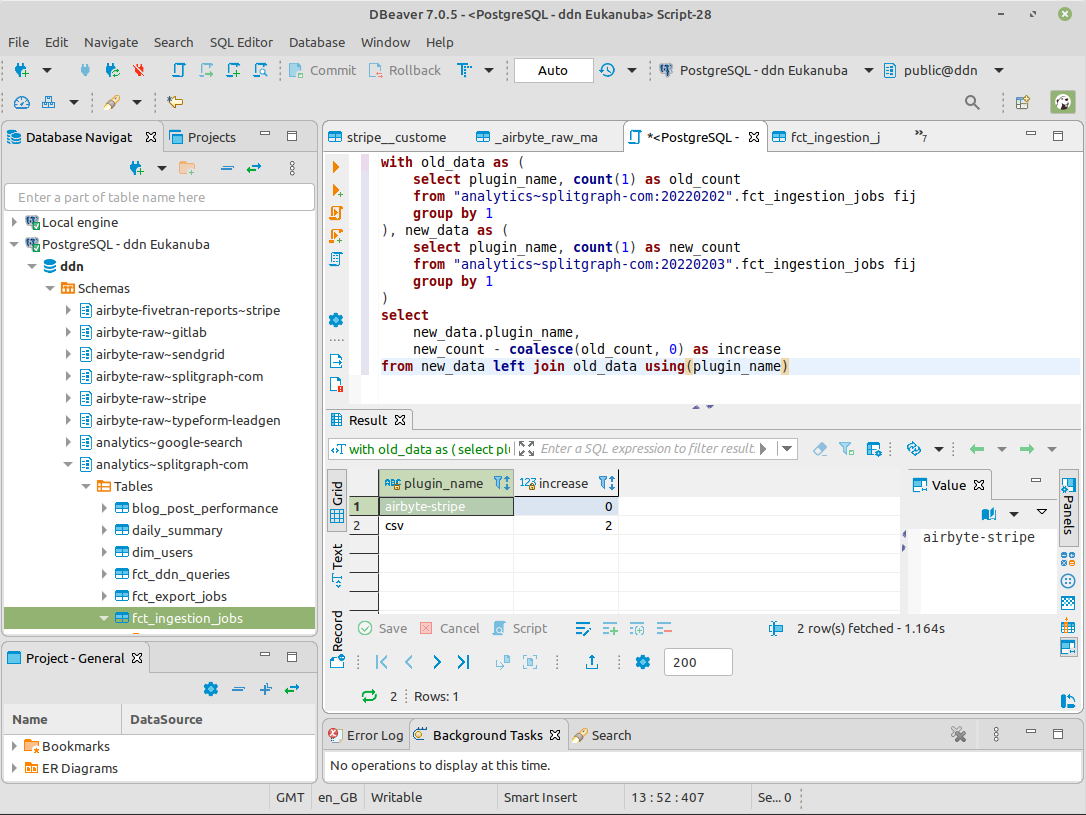
Interested in seeing how this works? Read on!
How it works
At its core, Splitgraph is a tool for building and sharing versioned "data products" (we call them data images). Each image is a snapshot of a PostgreSQL schema that you can freely move around and query.
dbt itself expects to be able to work against a database with a single shared namespace. It handles multitenancy by letting you build a dataset in a schema with a custom prefix. Each dbt user uses a separate target schema. This means their models don't step on the actual production models. See the dbt documentation for more details.
This presents some challenges in how we integrate Splitgraph Cloud with dbt.
We talked a bit about how the open-source Splitgraph library can work with dbt in a previous blog post. When running it in a managed fashion, we need to be able to automate all these steps.
Roughly, here's what we do:
- When a user adds a dbt project to Splitgraph, introspect it and let the user select which models they want to build in their dataset
- When running the dbt project:
- Set up a temporary Splitgraph engine
- Set the dbt sources to point to specific Splitgraph datasets required by it
- Set the dbt target to a specific schema on the engine
- Run dbt
- Run
sgr committo build the image and push it out
Introspection
This is a step that isn't required when using splitgraph.yml. However, we are currently working on a GUI to add data sources to Splitgraph. The first part of this workflow will be a "preview" stage. When you input the connection parameters, Splitgraph will introspect it and return a list of tables it discovered in the data source.
In case of dbt, we perform introspection by compiling your dbt project and extracting its manifest file. Here's the code.
Then, we parse the manifest file and load a list of models in it (code). Each model will become a table in your Splitgraph image.
Patching sources
This is the part of the plugin configuration that's responsible for it:
sources:
- dbt_source_name: airbyte_raw
namespace: airbyte-raw
repository: splitgraph-com
- dbt_source_name: stopforumspam
namespace: analytics
repository: stopforumspam
The dbt plugin crawls the project for all source references (code). It then rewrites each source's schema to point to a temporary schema. This temporary schema has the dependent Splitgraph image checked out in layered querying mode.
Here's an example of our dbt YAML file defining sources:
version: 2
sources:
- name: airbyte_raw
schema: "airbyte-raw/splitgraph-com"
tables:
- name: _airbyte_raw_celery_events_raw
- name: _airbyte_raw_gql_api_calls_raw
# ...
- name: stopforumspam
schema: "analytics/stopforumspam"
tables:
- name: listed_email_365_all
- name: listed_ip_365_ipv46_all
- name: listed_username_365_all
The schema in this case is what the plugin patches out. The default value for the schema is the standard Splitgraph format of namespace/repository. This is to make local development easier (more below).
Running dbt
We make a special profile to run dbt against the Splitgraph engine and get it to write the output to a temporary schema. Note that this won't capture cases where a dbt model uses a custom schema.
Finally, we run sgr commit to build the image. We also give it a versioned tag and push it out. At this point, it becomes just another dataset in our catalog that we can query with any SQL client.
In our case, we point Metabase at this dataset to build beautiful BI dashboards.
Local development
Developing the dbt model with this method is more complex than just running dbt against a data warehouse. We have plans to improve this.
In the meantime, here's how you can do local development.
First, you'll need to install sgr and set up a Splitgraph engine.
Then, set up a dbt profile file to work with the engine:
$ cat ~/.dbt/profiles.yml
splitgraph:
outputs:
prod:
dbname: splitgraph
# Change the connection parameters to the ones
# you set up for the engine
host: 127.0.0.1
pass: password
port: 6432
schema: my_target_schema
threads: 32
type: postgres
user: sgr
target: prod
Then, set up the source datasets. We'll be checking them out on the local engine into the namespace/repository PostgreSQL schemas. This is the reason we default to schema: "namespace/repository" in the dbt source file:
sgr clone my-source/repo:latest
sgr checkout --layered my-source/repo:latest
Finally, run the model:
dbt build --profile splitgraph
Future plans
Integrating the dbt docs site
Every dbt model comes with plenty of metadata about model and column meanings as well as tests. dbt uses this to generate its docs site.
Splitgraph could extend on its dbt manifest parsing and ingest that metadata as well. It would then be able to display it in the repository's overview page.
We could even integrate this with Splitgraph's lineage tracking features. This would let you click through to the source datasets for each built dbt model and query them.
Cataloging dbt models built on other warehouses
Splitgraph also supports live querying (data federation). Instead of running the dbt model itself, it could parse the manifest for a dbt project built in another data warehouse (Snowflake, Redshift, BigQuery etc). It would then create a set of repositories pointing to the data in that warehouse.
Autogenerating dbt models
With plenty of sources to come to Splitgraph, the next question will be how to make them immediately usable to people ingesting this data.
We could include some simple pre-generated queries for commonly used data sources. For example, when adding your data from Stripe, you could see a sample query for your monthly revenue.
We've done some research on feasibility of this. As part of that, we recently published an Airbyte-to-Fivetran Stripe adapter to dbt Hub. This package converts the Stripe data loaded by Airbyte into a format that's usable by Fivetran's Stripe dbt package.
Writeable DDN
The local development story with running dbt models on Splitgraph is a bit lacking. Ideally, a user would be able to run dbt on the Splitgraph DDN without running a local Splitgraph engine.
This will involve us building the ability to write to the DDN, including support for CREATE TABLE AS statements that dbt uses to build models.
Conclusion
In this post, we talked about Splitgraph Cloud's support for dbt models and did an in-depth dive of how it works and how we use it ourselves.
On our GitHub, you can find a similar self-contained example of this feature. It uses a GitHub Action to build a dataset of top commodity exporters in each country.
We also discussed our future ideas for dbt support. If you have any ideas or use cases to share, feel free to drop us an e-mail. If you're interested in a similar setup, get in touch and join our private beta!
Splitgraph
Made with


on four continents.