Splitgraph has been acquired by EDB! Read the blog post.
Supercharging dbt with Splitgraph: versioning, sharing, cross-DB joins
We discuss how you can use Splitgraph with dbt to add versioning and cross-database joins to dbt models. We also show how to use dbt to reference Splitgraph datasets, including through a purpose-built Splitgraph adapter.
Note (December 2021): We started using dbt more seriously for our own data stack, together with Airbyte and Splitgraph Cloud. Check out the blog post here!
Splitgraph is a data management, building and sharing tool inspired by Docker and Git that works on top of PostgreSQL and integrates seamlessly with anything that uses PostgreSQL.
dbt is a tool for transforming data inside of the data warehouse that allows users to build up transformations from reusable and versionable SQL snippets.
In this article, we'll talk about how Splitgraph can enhance dbt by:
- Adding versioning, packaging and sharing to dbt models
- Allowing dbt to join data across multiple databases using foreign data wrappers
- Giving dbt access to over 40,000 datasets hosted on or queryable through Splitgraph
Prerequisites
To run these examples, you need dbt, Docker and Docker Compose.
You also need to have sgr installed. We offer installation instructions for the three major operating systems, using PyPI, Git, or as a single self-contained binary.
If you have a working Python environment, the easiest way to get dbt and Splitgraph is by running
$ pip install splitgraph dbt
The source code for these examples is located on our GitHub. You will need to clone the Splitgraph repository to run these examples.
Versioning dbt models
The Splitgraph engine is based on PostgreSQL. Splitgraph's versioning runs on top of the SQL standard, using audit triggers. This means that any PostgreSQL client can interact with Splitgraph.
This example runs dbt's Jaffle Shop sample project on top of Splitgraph, switching between different versions of the source dataset and examining their effects on the built dbt model.
The code for this example is in the examples/dbt subdirectory. We will be running all commands relative to it.
Preparing data for dbt
Start the Compose stack with the Splitgraph engine and initialize it:
$ docker-compose up -d
$ sgr init
Clone the Jaffle Shop project:
$ git clone https://github.com/fishtown-analytics/jaffle_shop.git
Ingest the CSV data from the example into Splitgraph:
$ sgr init raw_jaffle_shop
$ sgr csv import -f jaffle_shop/data/raw_customers.csv -k id raw_jaffle_shop customers
$ sgr csv import -f jaffle_shop/data/raw_orders.csv -k id -t order_date timestamp raw_jaffle_shop orders
$ sgr csv import -f jaffle_shop/data/raw_payments.csv -k id raw_jaffle_shop payments
Snapshot the data, turning it into a versioned Splitgraph image:
$ sgr commit raw_jaffle_shop
$ sgr tag raw_jaffle_shop asof_20180409
Inspect the dataset:
$ sgr show raw_jaffle_shop:asof_20180409
Image raw_jaffle_shop:3acc047a24d35f2a50ce4d20b6ebff9fbabb0ecccc4f5ef8fad0e929a6990e08
Created at 2020-06-23T20:53:42.830905
Size: 7.58 KiB
Parent: 0000000000000000000000000000000000000000000000000000000000000000
Tables:
customers
orders
payments
$ sgr table raw_jaffle_shop:asof_20180409 orders
Table raw_jaffle_shop:3acc047a24d35f2a50ce4d20b6ebff9fbabb0ecccc4f5ef8fad0e929a6990e08/orders
Size: 1.73 KiB
Rows: 99
Columns:
id (integer, PK)
user_id (integer)
order_date (timestamp without time zone)
status (character varying)
Objects:
o7e3ffa6e2141edde30498e4c4a6a2b510d8b7e479081aafe154d31ca4436bd
The status column in the raw_orders table in the initial dataset can change through time. Pretend that this has happened and that some jaffles were returned.
$ sgr sql "UPDATE raw_jaffle_shop.orders SET status = 'returned' WHERE status = 'return_pending' OR order_date = '2018-03-26'"
Now, run sgr diff to see which rows have changed:
$ sgr diff -v raw_jaffle_shop
Between 3acc047a24d3 and the current working copy:
customers: no changes.
orders: added 5 rows, removed 5 rows.
- (23, 22, datetime.datetime(2018, 1, 26, 0, 0), 'return_pending')
- (52, 54, datetime.datetime(2018, 2, 25, 0, 0), 'return_pending')
- (84, 70, datetime.datetime(2018, 3, 26, 0, 0), 'placed')
- (85, 47, datetime.datetime(2018, 3, 26, 0, 0), 'shipped')
- (86, 68, datetime.datetime(2018, 3, 26, 0, 0), 'placed')
+ (23, 22, datetime.datetime(2018, 1, 26, 0, 0), 'returned')
+ (52, 54, datetime.datetime(2018, 2, 25, 0, 0), 'returned')
+ (84, 70, datetime.datetime(2018, 3, 26, 0, 0), 'returned')
+ (85, 47, datetime.datetime(2018, 3, 26, 0, 0), 'returned')
+ (86, 68, datetime.datetime(2018, 3, 26, 0, 0), 'returned')
payments: no changes.
Commit this dataset and check out the original image:
$ sgr commit raw_jaffle_shop
$ sgr tag raw_jaffle_shop asof_20180410
$ sgr checkout raw_jaffle_shop:asof_20180409
We now have two versions of the original Jaffle shop dataset. Let's run the example dbt model on both of them.
Running the dbt model
This is the dbt profile for this project (see .dbt/profiles.yml):
jaffle_shop:
target: splitgraph
outputs:
splitgraph:
type: postgres
host: localhost
user: sgr
pass: supersecure
port: 5432
dbname: splitgraph
# The final schema that dbt writes to is a combination of this profile schema
# and the schema specified in the model.
schema: "dbt_jaffle"
threads: 4
Run dbt debug to make sure your connection is set up properly:
$ dbt debug --profiles-dir .dbt --project-dir jaffle_shop
Initialize a Splitgraph repository for the built dbt model:
$ sgr init dbt_jaffle
Now, check out the version of the dbt project that uses data from the warehouse (rather than seed data) and run the models:
$ cd jaffle_shop
jaffle_shop $ git checkout demo/master --force
jaffle_shop $ dbt run --profiles-dir ../.dbt
jaffle_shop $ cd ..
Commit the built dataset as a Splitgraph image. Note that Splitgraph doesn't currently support storing views that dbt uses as a staging point for the initial data, so it will ignore them.
$ sgr commit dbt_jaffle
$ sgr tag dbt_jaffle asof_20180409
Let's check out the new version of the initial data and run dbt against it as well.
$ sgr checkout raw_jaffle_shop:asof_20180410
$ cd jaffle_shop
jaffle_shop $ dbt run --profiles-dir ../.dbt
jaffle_shop $ cd ..
Snapshot the new output to make another Splitgraph image.
$ sgr commit dbt_jaffle
$ sgr tag dbt_jaffle asof_20180410
We now have two versions of the source and the target dataset.
$ sgr log -t raw_jaffle_shop
0000000000 2020-06-23 20:53:40
└ 3acc047a24 [asof_20180409] 2020-06-23 20:53:42
└ 32c7819c9d [HEAD, asof_20180410, latest] 2020-06-23 20:53:45
$ sgr log -t dbt_jaffle
0000000000 2020-06-23 20:53:48
└ 98478a40d1 [asof_20180409] 2020-06-23 20:53:53
└ dce4e970fa [HEAD, asof_20180410, latest] 2020-06-23 20:53:58
Using sgr diff, you can inspect the difference between the two datasets that dbt built.
$ sgr diff dbt_jaffle asof_20180409 asof_20180410 --verbose
Between 98478a40d1c2 and dce4e970faf7:
customer_orders: no changes.
customer_payments: no changes.
dim_customers: no changes.
fct_orders: added 5 rows, removed 5 rows.
- (23, 22, datetime.datetime(2018, 1, 26, 0, 0), 'return_pending', 0, 0, 0, 23, 23)
- (52, 54, datetime.datetime(2018, 2, 25, 0, 0), 'return_pending', 0, 0, 15, 0, 15)
- (84, 70, datetime.datetime(2018, 3, 26, 0, 0), 'placed', 0, 0, 25, 0, 25)
- (85, 47, datetime.datetime(2018, 3, 26, 0, 0), 'shipped', 0, 0, 17, 0, 17)
- (86, 68, datetime.datetime(2018, 3, 26, 0, 0), 'placed', 0, 23, 0, 0, 23)
+ (23, 22, datetime.datetime(2018, 1, 26, 0, 0), 'returned', 0, 0, 0, 23, 23)
+ (52, 54, datetime.datetime(2018, 2, 25, 0, 0), 'returned', 0, 0, 15, 0, 15)
+ (84, 70, datetime.datetime(2018, 3, 26, 0, 0), 'returned', 0, 0, 25, 0, 25)
+ (85, 47, datetime.datetime(2018, 3, 26, 0, 0), 'returned', 0, 0, 17, 0, 17)
+ (86, 68, datetime.datetime(2018, 3, 26, 0, 0), 'returned', 0, 23, 0, 0, 23)
order_payments: no changes.
Let's also run a sample query against the two images: how much in bank transfer refunds did we process?
$ sgr sql -i dbt_jaffle:asof_20180409 "SELECT sum(bank_transfer_amount) FROM fct_orders WHERE status = 'returned'"
3
$ sgr sql -i dbt_jaffle:asof_20180410 "SELECT sum(bank_transfer_amount) FROM fct_orders WHERE status = 'returned'"
60
Joining between PostgreSQL and MongoDB
Splitgraph has first-class support for PostgreSQL foreign data wrappers, allowing you to access other databases directly from your Splitgraph instance without having to ETL them into Splitgraph. To the client application, a foreign table behaves exactly the same as a local table.
We discussed foreign data wrappers in a previous blog post.
This example will show you how to run dbt against a Splitgraph engine to join data between PostgreSQL and MongoDB. You can easily extend it to run operations across any databases for which a foreign data wrapper is available. Check the PostgreSQL wiki for a list of available PostgreSQL foreign data wrappers.
The code for this example is in the examples/dbt_two_databases subdirectory.
The Docker Compose stack for this example contains:
- a Splitgraph engine
- a PostgreSQL instance with some sample data
- a MongoDB instance with more sample data
Here's an architecture diagram of this setup:
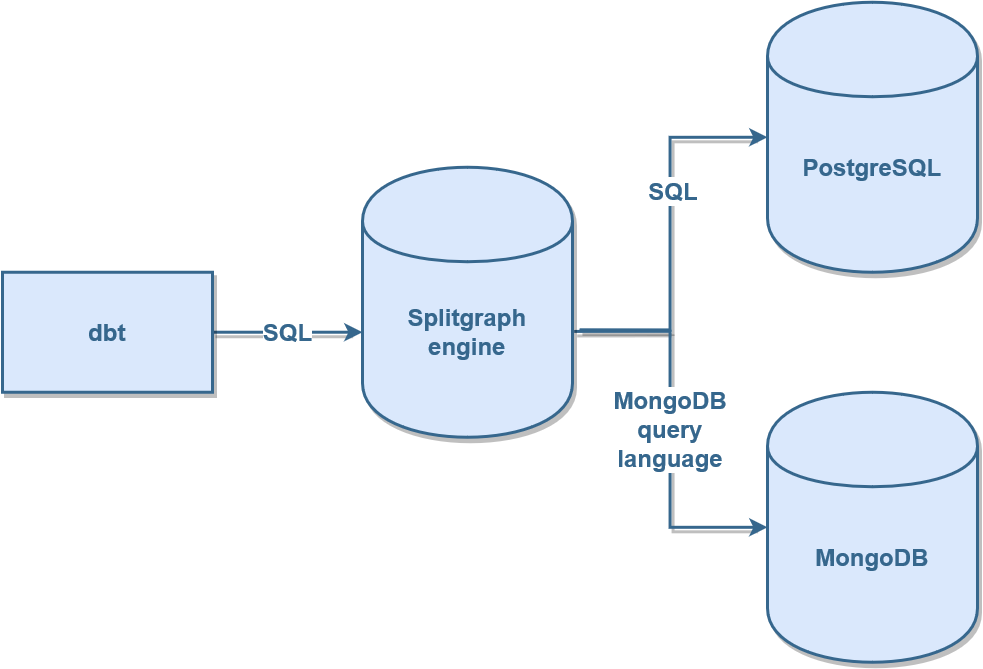
We will first "mount" the two databases into the Splitgraph engine and then run a dbt model. The model will run an SQL JOIN between the data in the two databases.
Mounting the databases into the Splitgraph engine
First, start the stack and test that Splitgraph and dbt can connect to it:
$ docker-compose up -d
$ sgr init
$ dbt debug --profiles-dir .dbt
Mount the PostgreSQL database
into your Splitgraph engine. This will create a schema fruits_data with a single table, fruits. When an SQL client queries this table, the foreign data wrapper will forward the query to the remote database and give the results back to the client.
$ sgr mount postgres_fdw fruits_data -c originuser:originpass@postgres:5432 -o @- <<EOF
{
"dbname": "origindb",
"remote_schema": "public"
}
EOF
Test that the data is now available on the engine. You can do this with any PostgreSQL client, but Splitgraph offers a shorthand to run SQL statements against the engine:
$ sgr sql "SELECT * FROM fruits_data.fruits"
1 apple
2 orange
3 tomato
Do the same thing with MongoDB. Because MongoDB is schemaless, we have to specify the schema that we wish our foreign table to have. Read the Splitgraph MongoDB documentation for more information.
$ sgr mount mongo_fdw order_data -c originro:originpass@mongo:27017 -o @- <<EOF
{
"orders":
{
"database": "origindb",
"collection": "orders",
"schema":
{
"name": "text",
"fruit_id": "numeric",
"happy": "boolean",
"review": "text"
}
}
}
EOF
Check we can get data from MongoDB too:
$ sgr sql "SELECT * FROM order_data.orders"
5f0c736093455fe435231159 Alex 1 False Was in transit for five days, arrived rotten.
5f0c736093455fe43523115a James 2 True
5f0c736093455fe43523115b Alice 3 True Will use in salad, great fruit!
Note that mongo_fdw adds the Mongo object ID column as the first column of all tables.
Running the dbt model
The dbt model consists of a simple JOIN statement:
with fruits as (
select fruit_id, name from fruits_data.fruits
),
orders as (
select name, fruit_id, happy, review
from order_data.orders
)
select fruits.name as fruit, orders.name as customer, review
from fruits join orders
on fruits.fruit_id = orders.fruit_id
Run it:
$ dbt run --profiles-dir .dbt
Running with dbt=0.17.0
Found 1 model, 0 tests, 0 snapshots, 0 analyses, 134 macros, 0 operations, 0 seed files, 0 sources
15:52:44 | Concurrency: 4 threads (target='splitgraph')
15:52:44 |
15:52:44 | 1 of 1 START table model dbt_two_databases.join_two_dbs.............. [RUN]
15:52:44 | 1 of 1 OK created table model dbt_two_databases.join_two_dbs......... [SELECT 3 in 0.33s]
15:52:44 |
15:52:44 | Finished running 1 table model in 0.47s.
Completed successfully
Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
Check the dataset that dbt built:
$ sgr sql "SELECT fruit, customer, review FROM dbt_two_databases.join_two_dbs"
apple Alex Was in transit for five days, arrived rotten.
orange James
tomato Alice Will use in salad, great fruit!
Using Splitgraph data with dbt
Even without any extra support, you can use Splitgraph images in your dbt models.
For example, you can check out a Splitgraph image into a schema and run dbt against that schema. You can even use layered querying to let dbt reference Splitgraph images that are hosted on other Splitgraph registries without having to clone them.
In addition, you can mount Socrata datasets on your Splitgraph engine. This lets dbt access over 40,000 open government datasets. For example:
$ sgr mount socrata chicago_data -o @- <<EOF
{
"domain": "data.cityofchicago.org",
"tables": {"fire_stations": "28km-gtjn"}
}
You can now reference the chicago_data.fire_stations table from dbt to query the Chicago Fire Stations dataset hosted by Socrata.
Splitgraph dbt adapter
Splitgraph also has a dbt adapter. It lets you reference Splitgraph images directly from your dbt model. This takes care of downloading the required parts of the Splitgraph image in the background.
This example will show you how to install the adapter and run a dbt model that uses Splitgraph data.
Unlike the previous examples, you will need to bring your own Splitgraph engine. You can create one with sgr engine add or start it with sgr engine start. Check the Splitgraph engine management documentation for more information.
Install the adapter by running:
$ pip install dbt-splitgraph
Add credentials for your Splitgraph engine to the dbt profiles.yml file (see the dbt documentation on information on the profile file):
default:
target: splitgraph
outputs:
splitgraph:
type: splitgraph
host: localhost
user: sgr
pass: password
port: 5432
dbname: splitgraph
schema: [some_schema]
threads: 4
Make sure that you've initialized the engine (sgr init). Also make sure that your .sgconfig file is either in ~/.splitgraph/.sgconfig or pointed to by the SG_CONFIG_FILE environment variable. If required, also log into the Splitgraph registry or your custom remote with Splitgraph images using sgr cloud login or sgr cloud login-api.
You can now reference Splitgraph images in your dbt models by schema-qualifying tables with the full Splitgraph image path (you can use hashes or tags).
The sample dbt model queries the latest Splitgraph Socrata index image to find the amount of datasets in each Socrata domain indexed by Splitgraph.
To run the model:
$ cd sample_project
sample_project $ dbt run # add `--profiles-dir ./.dbt`
# to use the sample profile
Running with dbt=0.17.0
Found 1 model, 0 tests, 0 snapshots, 0 analyses, 151 macros, 0 operations, 0 seed files, 0 sources
14:35:23 | Concurrency: 4 threads (target='splitgraph')
14:35:23 |
14:35:23 | 1 of 1 START table model adapter_showcase.use_splitgraph_data........ [RUN]
14:35:24 | 1 of 1 OK created table model adapter_showcase.use_splitgraph_data... [SELECT 206 in 1.42s]
14:35:24 |
14:35:24 | Finished running 1 table model in 1.54s.
Check the built dataset:
$ sgr sql "SELECT * FROM adapter_showcase.use_splitgraph_data ORDER BY count DESC"
www.datos.gov.co 12190
data.cityofnewyork.us 2126
opendata.utah.gov 2019
data.edmonton.ca 1025
data.wa.gov 944
performance.seattle.gov 867
data.usaid.gov 727
data.austintexas.gov 703
data.ny.gov 647
data.oregon.gov 641
...
Conclusion
In this article, we discussed how Splitgraph can complement dbt by adding versioning to dbt models or allowing dbt to go beyond a single database.
If you're interested in learning more about Splitgraph, you can check our frequently asked questions section, follow our quick start guide or visit our website.
Splitgraph
Made with


on four continents.