Socrata
Introduction
The Socrata data platform hosts tens of thousands of government datasets. Governments large and small publish data on crime, permits, finance, healthcare, research, performance, and more for citizens to use. They publish the data to a white-labeled "data portal" provided by Socrata. There are over 200 of these data portals, and Splitgraph indexes the data from all of them.
sgr has first-class support for querying Socrata datasets through SQL and
using them in Splitfiles. Support for Socrata is
implemented as a foreign data wrapper.
This allows you to use sgr as a PostgreSQL-to-Socrata connector. Any
PostgreSQL application, client or dashboarding tool can query Socrata datasets
through sgr and even run joins on datasets from different Socrata data portals
or between Socrata datasets and Splitgraph images.
Usage
Each dataset has a unique "four-by-four" (a Socrata dataset ID, for example,
28km-gtjn) and is hosted on a certain domain ("data portal"), for example,
data.cityofchicago.org. Use the sgr client to mount the dataset:
sgr mount socrata chicago_data -o @- <<EOF
{
"domain": "data.cityofchicago.org",
"tables": {"fire_stations": "28km-gtjn"},
"app_token": "YOUR_APP_TOKEN"
}
EOF
This will create a table fire_stations in chicago_data schema on your engine
that, when queried, will rewrite requests into
SoQL queries and forward them to the
Socrata server, querying the relevant dataset. In this case, it will query the
Chicago Fire Stations dataset.
sgr will automatically discover the table schema and other metadata from the
Socrata API.
The app token is optional but requests without it are anonymous and Socrata may throttle them. See the Socrata API reference on how to get an app token.
Finally, the tables field is optional as well. Without it, sgr will mount
all datasets provided by that domain as foreign tables, giving the tables
human-readable names consisting of the Socrata dataset name and the Socrata
dataset ID, for example, building_violations_22u3_xenr. This will not download
any actual data from Socrata but will let you explore all data on that domain in
any PostgreSQL client.
Full mounting takes a few seconds on a domain that serves up 500 datasets.
Note that sgr currently only supports Socrata datasets (not data lenses,
calendars, external links etc).
Discovering Socrata datasets
Splitgraph catalog
Splitgraph maintains a metadataset of available Socrata datasets at
splitgraph/socrata. The easiest way to search through
this catalog from the command line is to clone the data image and query it:
$ sgr clone splitgraph/socrata:latest --download-all
$ sgr sql -i splitgraph/socrata:latest \\
"SELECT domain, id, name FROM datasets WHERE name ILIKE '%covid%'"
data.austintexas.gov 4p54-9544 Austin Code COVID-19 Complaint Cases
data.calgary.ca uq24-jkwv COVID-19 Requests
data.cambridgema.gov 4nyp-vuze OLD - Confirmed Cambridge COVID-19 Cases - OLD
data.cambridgema.gov inw8-ircw Confirmed COVID-19 Cases in Cambridge
data.cambridgema.gov tdt9-vq5y COVID-19 Cumulative Cases by Date
data.cdc.gov 9bhg-hcku Provisional COVID-19 Death Counts by Sex, Age, and State
data.cdc.gov b58h-s9zx Provider Relief Fund COVID-19 High-Impact Payments
data.cdc.gov hc4f-j6nb Provisional Death Counts for Coronavirus Disease (COVID-19)
data.cdc.gov hk9y-quqm Conditions contributing to deaths involving coronavirus disease 2019 (COVID-19), by age group, United States.
data.cdc.gov kn79-hsxy Provisional COVID-19 Death Counts in the United States by County
...
This is not an exhaustive list: it is populated from the Socrata Discovery API at https://api.us.socrata.com/api/catalog/v1. See the Socrata Discovery API documentation for reference.
On the web, you can also use the dataset search feature of Splitgraph, explore featured data, or explore data topics.
Other Socrata domains
You can query any Socrata dataset through sgr, not just those that are indexed
in the catalog. If you have found a dataset you wish to query (on your internal
Socrata instance or through a search engine such as the
Open Data Network), just note its domain and
dataset ID and use the sgr mount command as normal. As long as the domain is a
Socrata data portal with API access, this will work.
Examples
Splitfile
FROM MOUNT socrata
'{"domain": "data.cityofchicago.org",
"tables": {"business_licenses": "r5kz-chrr",
"business_owners": "ezma-pppn"}}'
IMPORT {
SELECT
bo.owner_first_name,
bo.owner_last_name,
bl.legal_name,
bl.address,
bl.city,
bl.license_id,
bl.expiration_date
FROM business_licenses bl
JOIN business_owners bo
ON bl.account_number = bo.account_number
WHERE bl.license_description = 'Tavern'
AND bl.expiration_date > '2020-05-01'
} AS chicago_bars
This Splitfile mounts two Socrata datasets:
Chicago Business Licenses
and Chicago Business Owners
and runs an IMPORT to join between them and
snapshot the data.
The result is a list of all bar owners in Chicago with current liquor licenses.
Exploring data with DBeaver
The Socrata Discover API in conjunction with sgr's mounting capabilities
allows you to explore Socrata data from any SQL client.
First, mount Socrata open data endpoints for Chicago, IL and Cambridge, MA:
$ sgr mount socrata chicago -o '{"domain": "data.cityofchicago.org"}'
Connecting to remote server...
Mounting Socrata domain...
Getting Socrata metadata
warning: Requests made without an app_token will be subject to strict throttling limits.
Loaded metadata for 504 Socrata tables
$ sgr mount socrata cambridge -o '{"domain": "data.cambridgema.gov"}'
Connecting to remote server...
Mounting Socrata domain...
Getting Socrata metadata
warning: Requests made without an app_token will be subject to strict throttling limits.
Loaded metadata for 137 Socrata tables
This doesn't actually load any data and only loads metadata for all available datasets, creating PostgreSQL foreign tables for each one of them. Such tables act as lightweight shims and most clients will treat them like normal tables (sometimes introspection may be different, or they may show up in a list of "foreign tables" rather than "tables").
Open a PostgreSQL client (instructions are available for
DataGrip,
pgAdmin or
other clients like pgcli or DBeaver)
and connect to the sgr engine. In these screenshots,
DBeaver is used.
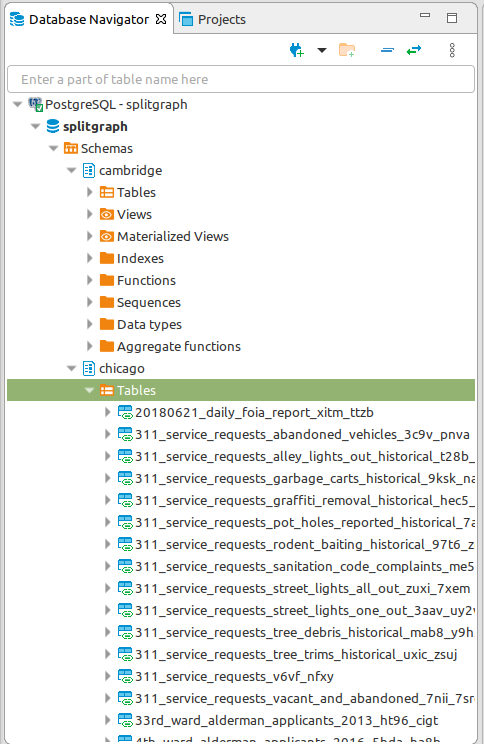
Chicago data is now mounted in the chicago schema and Cambridge in
cambridge. Every table maps to a Socrata dataset, with the name being
automatically generated from the dataset name and the Socrata ID.
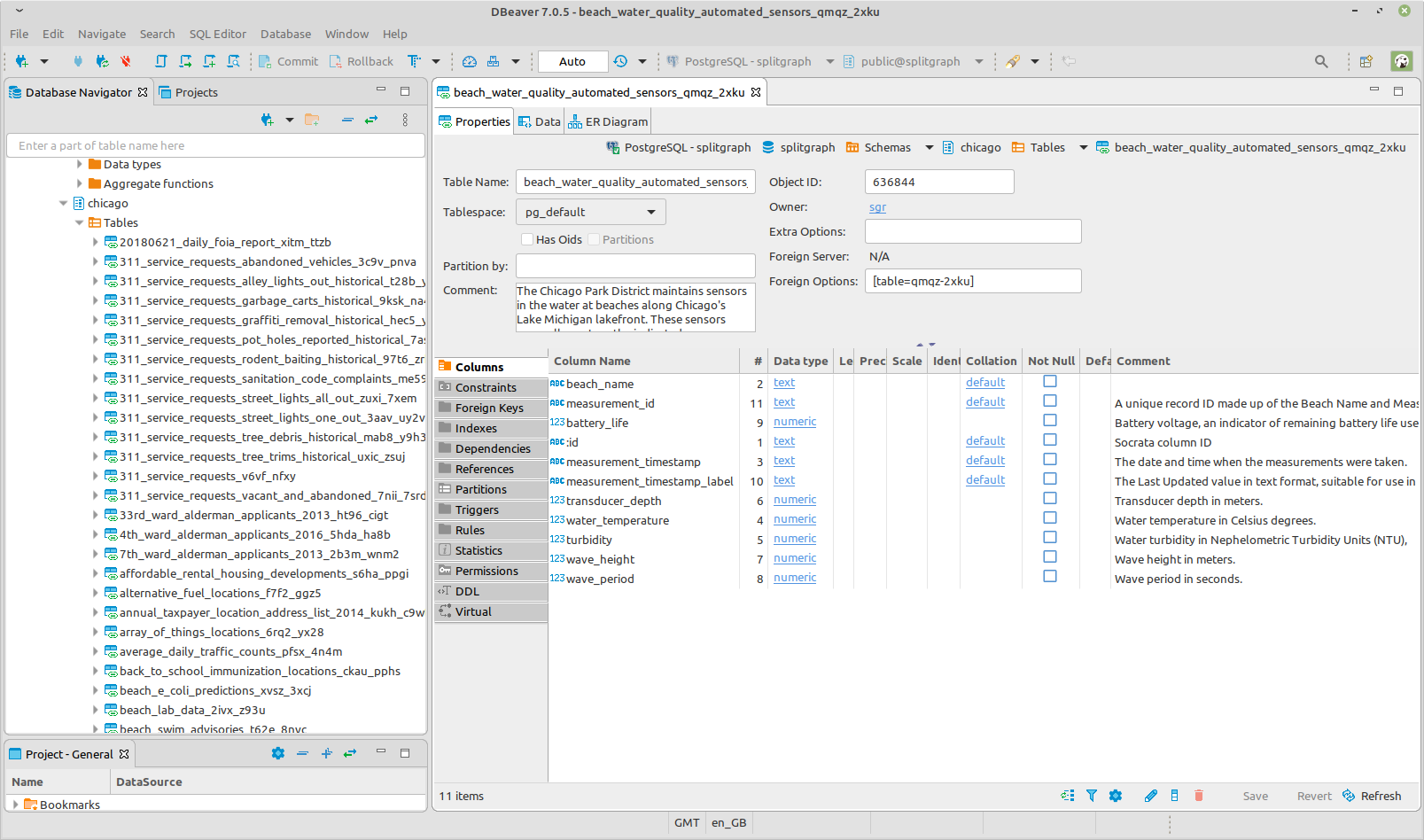
sgr also grabs descriptions for each dataset and every column from Socrata
metadata, if it exists. These descriptions are added as PostgreSQL COMMENT
entries on tables and columns.
sgr loads mounted data on demand, similar to
layered querying. It only sends queries to
Socrata when the client introspects or queries a table.
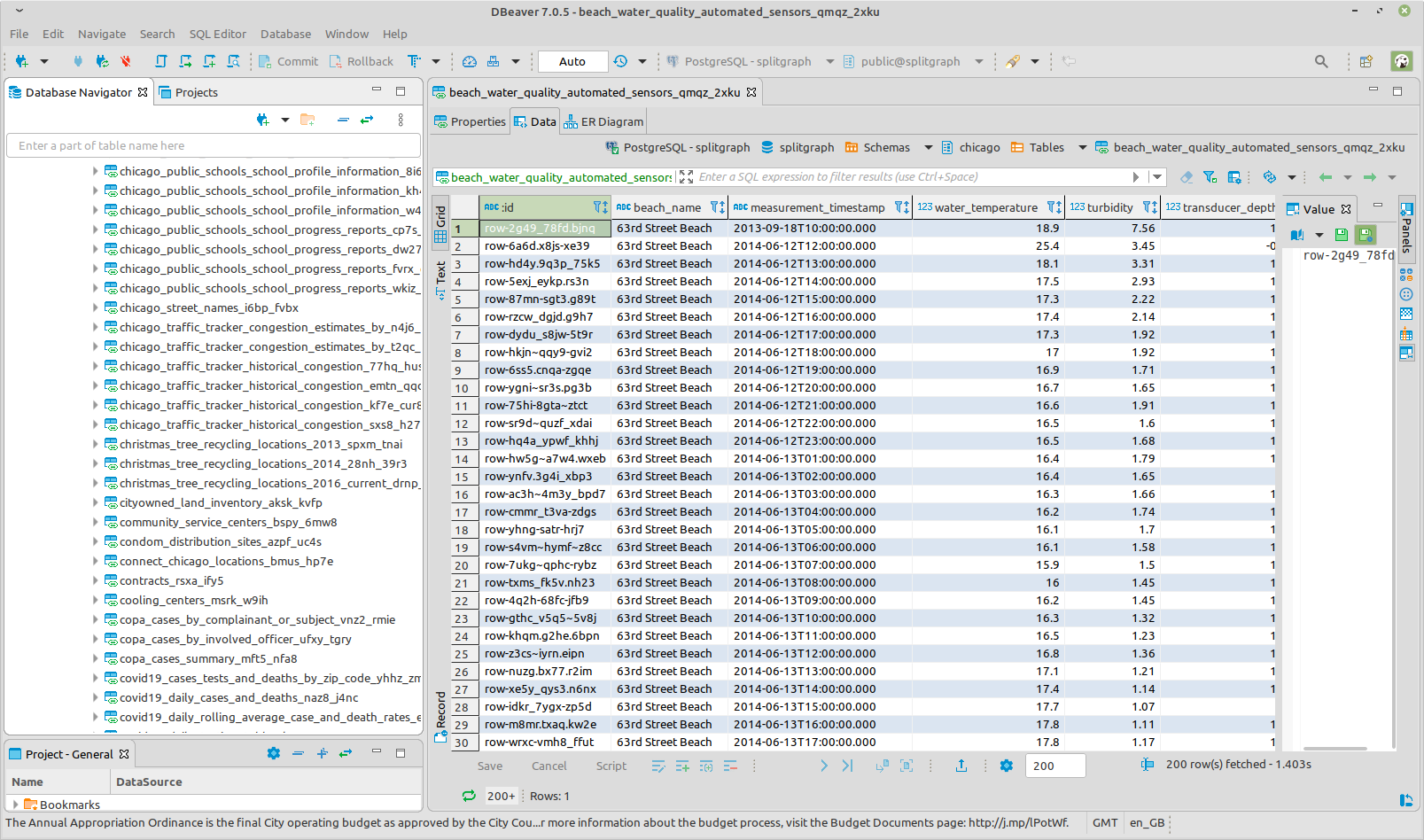
In addition, you can use filters, ORDER, LIMIT and OFFSET clauses in your
queries, which sgr will rewrite into
SoQL queries when sending them to
Socrata, so your local sgr instance doesn't need to load the whole dataset.
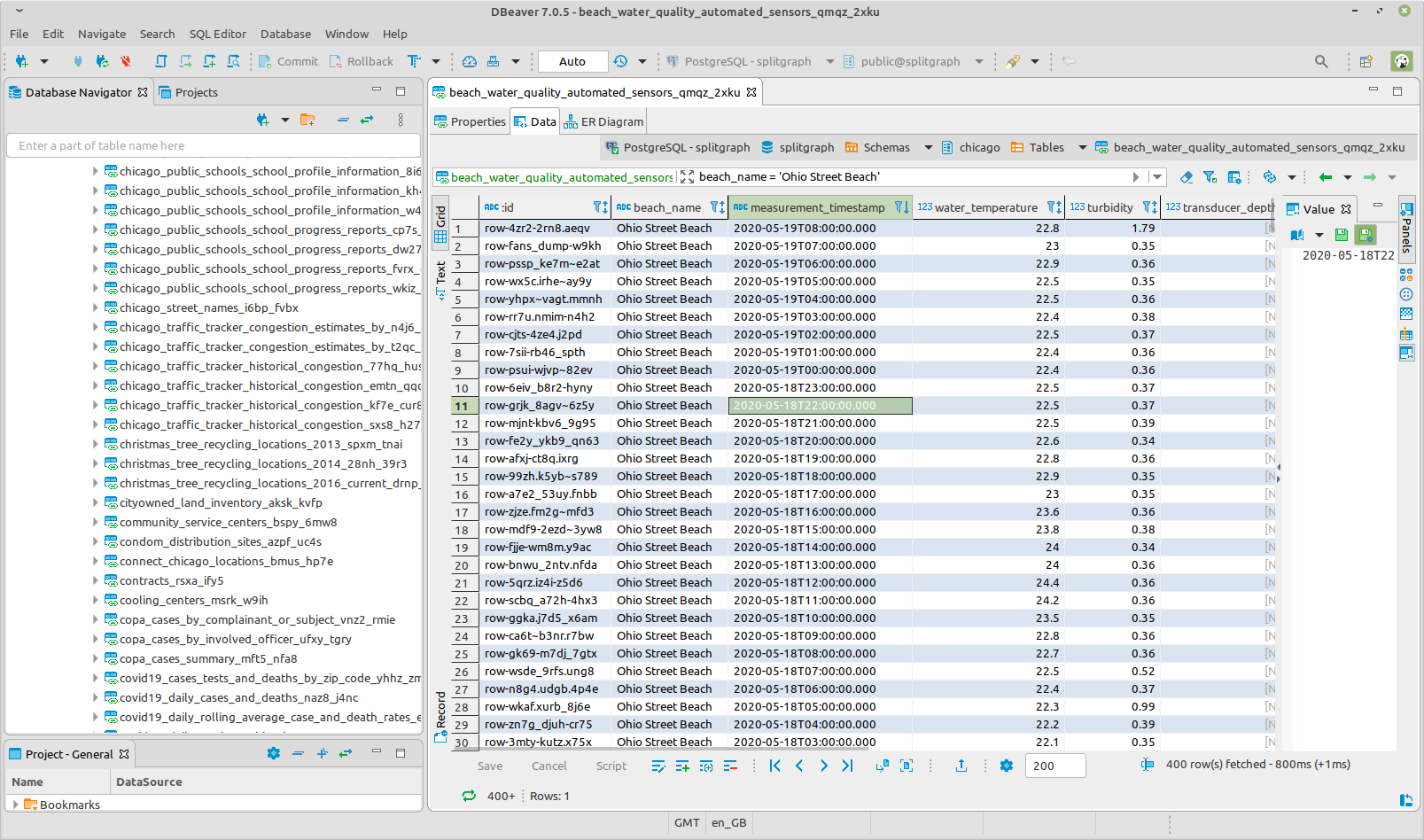
Using Metabase to join and plot data from multiple data portals
In this section, we'll use Metabase, a powerful
visualization and dashboarding tool, to plot a table that joins data from two
distinct Socrata data portals. Normally, this would involve some ETL jobs and a
Jupyter notebook, but with sgr, we'll be able to do this directly in one
simple SQL query.
Follow the Metabase integration guide to
set up Metabase with sgr and make sure the Chicago and Cambridge data
endpoints are mounted (see previous section).
First, let's try plotting the
COVID-19 Daily Cases and Deaths
Socrata dataset (Socrata ID naz8-j4nc):
SELECT
lab_report_date, cases_total
FROM
chicago.covid19_daily_cases_deaths_and_hospitalizations_naz8_j4nc chicago_cases
ORDER BY lab_report_date ASC;
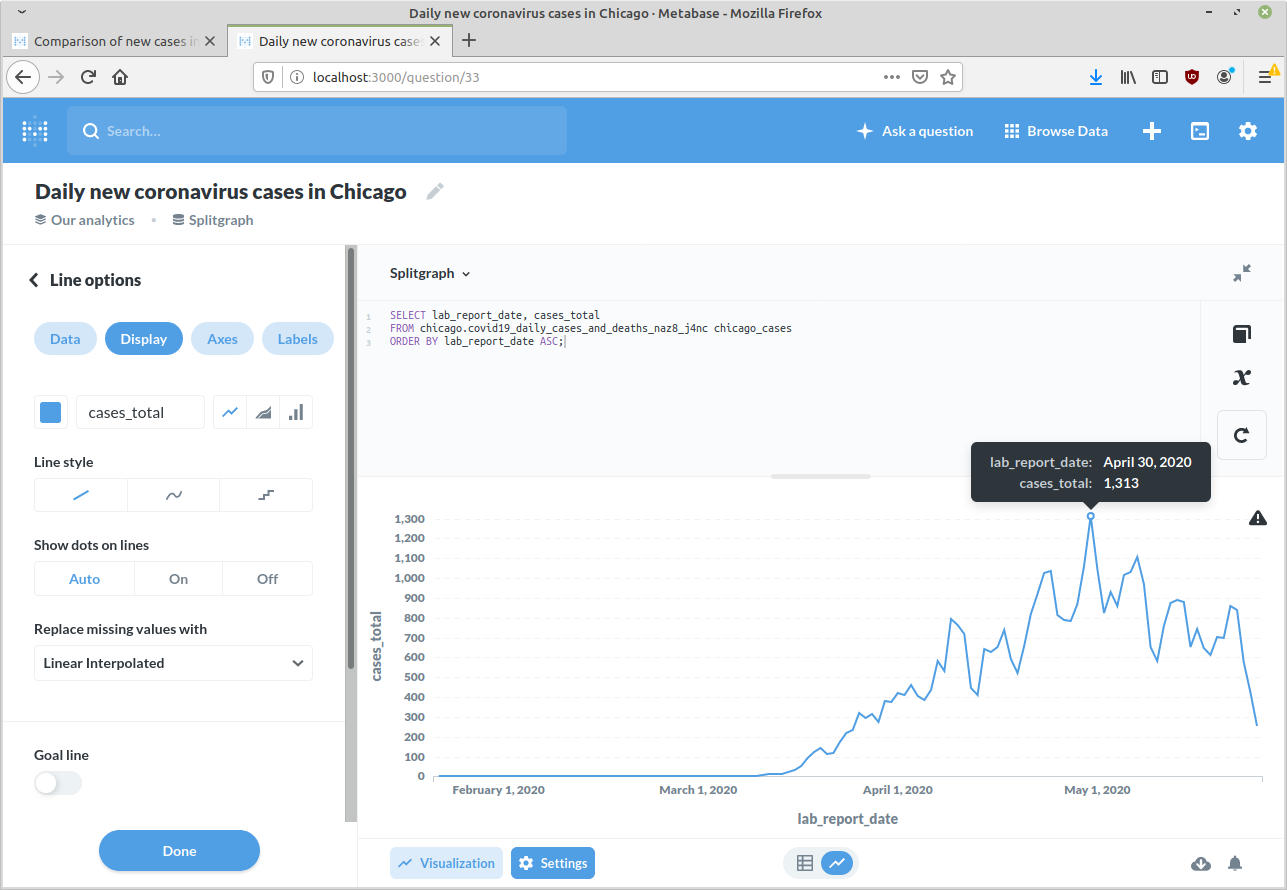
Note that this is run against the chicago schema that has all available tables
from the data.cityofchicago.org Socrata
domain mounted. You can also mount just the table you're interested in and give
it a more readable name:
$ sgr mount socrata -o '{"domain": "data.cityofchicago.org", \\
"tables": {"covid_cases": "naz8-j4nc"}}'
Now, let's compare new daily cases in Chicago and Cambridge. You can do this
with a simple JOIN. Of course referential integrity is not guaranteed to
exist, but assuming the data is properly cleaned, we just have to make sure both
tables are in terms of the date, rather than the timestamp, so that they can be
matched up:
(Note: If you do need to clean data, you could always load it into a Splitgraph image, perform the necessary modifications on it, and then use that image as the source instead of the mounted data).
SELECT
cambridge_cases.date AS date,
chicago_cases.cases_total AS chicago_daily_cases,
cambridge_cases.new_positive_cases AS cambridge_daily_cases
FROM
chicago.covid19_daily_cases_deaths_and_hospitalizations_naz8_j4nc chicago_cases
FULL OUTER JOIN
cambridge.covid19_case_count_by_date_axxk_jvk8 cambridge_cases
ON
date_trunc('day', chicago_cases.lab_report_date) = cambridge_cases.date::timestamp
ORDER BY date ASC;
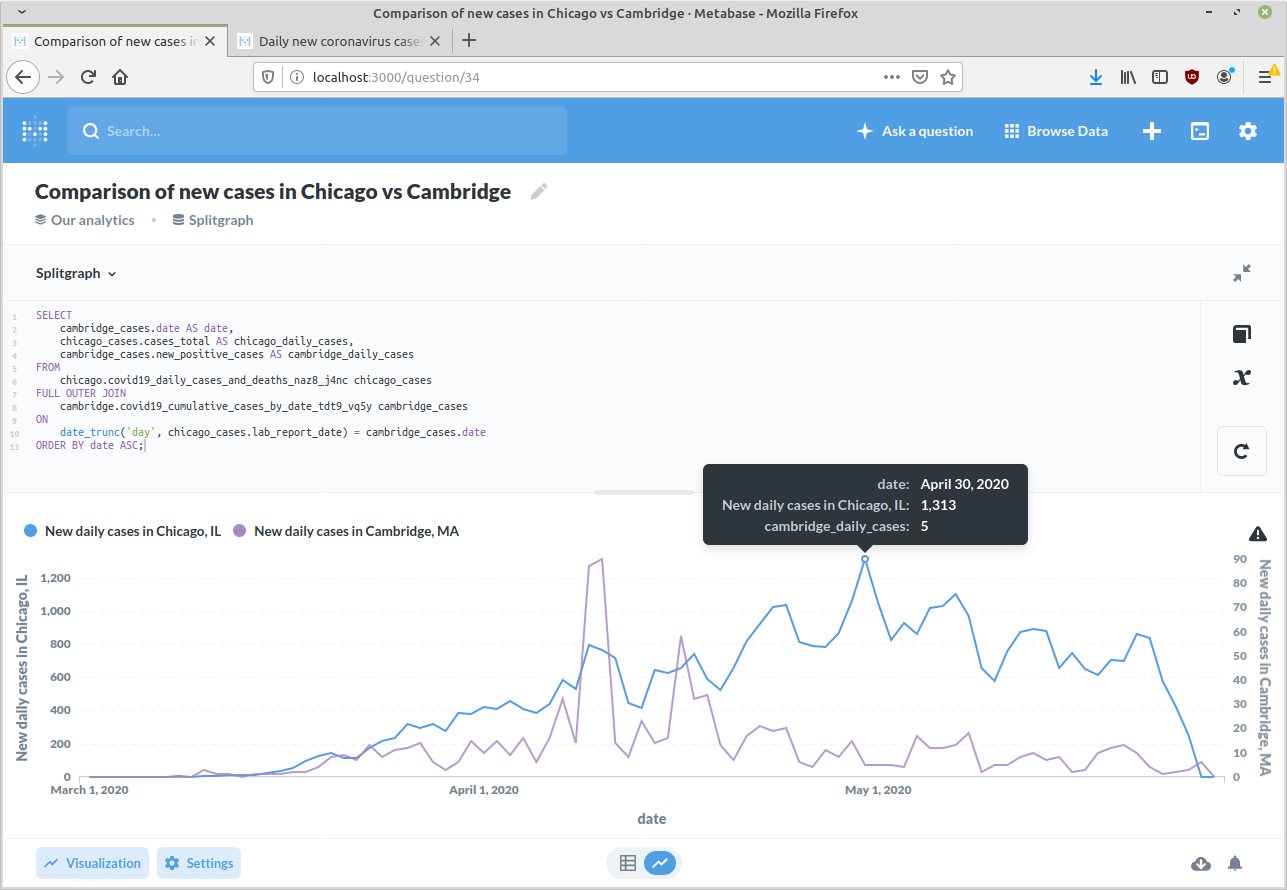
Behind the scenes, this queries the Chicago COVID-19 Daily Cases and Deaths and the Cambridge COVID-19 Cumulative Cases by Date Socrata datasets using SoQL and the actual JOIN is performed in PostgreSQL. However, Metabase and any other PostgreSQL client doesn't need to know about that; to them, these look like normal PostgreSQL tables.
Licensing and contact
Socrata datasets are not hosted by Splitgraph (although many are indexed by
Splitgraph) and the sgr engine queries them through the public Socrata API.
While most datasets hosted by Socrata are in the public domain, you should
always check the dataset's metadata for support, licensing information and
contact information.

