Splitgraph has been acquired by EDB! Read the blog post.
Parsing pgSQL with tree-sitter in WASM
We used tree-sitter to show the tables referenced in the query inside the Splitgraph Console.
The Splitgraph Console now analyzes the SQL query on the fly and displays the referenced tables in the sidebar for easier query comprehension. The feature is powered by tree-sitter running in WASM.
Interested in how we got it working? Read on!
The Splitgraph Console offers an IDE-like experience for interacting with Splitgraph and the data it exposes. One fundamental feature is the query editor. It resembles a code editor and is used for editing SQL (PostgreSQL, in fact) queries, rather than files.
The query editor has smart features like:
autocomplete
We use
pgclion the backend to retrieve the completions.syntax highlighting
We use the SQL Monaco language configuration, which uses the Monarch library under the hood.
One interesting feature we wanted to have was to introspect the query and display the tables it references. This would let the user quickly understand and interact with a subset of repositories and tables, rather than all repositories and tables within some namespace.
We implemented this feature using tree-sitter compiled to WASM (web-tree-sitter) so the parsing happens within the user's browser. The rest of this article outlines the problems faced and the decisions we took to get the feature working.
Parsing in the browser or on the server
The first question we had to answer was whether the parsing process should happen in the browser, like our syntax highlighting, or on the server, like our autocomplete.
There are pros and cons to both approaches:
parsing in the browser has a higher initial cost (fetching and initializing the parser), but offers faster feedback during editing, and transfers less data during long editing sessions
the browser can only execute JavaScript or WASM. The parser would have to be compiled to either of these languages. This limits our choices, as we cannot run arbitrary existing parsers.
either the browser or the server have to do more work to parse the query. For in-browser parsing, this could be slow for low-end devices. For server parsing, we could DDoS our servers by having many users ask for parsing of their queries.
At this point, either approach would work. We had a slight preference for doing in-browser parsing for its lower latency and being able to use the parsed AST for more features in the future.
Existing SQL parsers
Parsing SQL is a popular problem which has many solutions in various languages.
libpg_query and its bindings
libpg_query is a C library for parsing PostgreSQL. It uses the same code that the PostgreSQL server uses. This makes the parsing the most accurate and spec-compliant.
There are bindings for using libpg_query in other languages:
pgsql-parser for Node.js
pg-query-emscripten for WASM (available in the browser)
pg_query.rs for Rust
Trivia: this is what Supabase's postgres_lsp uses to parse pgSQL.
The importance of syntax error recovery
One major downside behind using any library based on libpg_query is that it
has no syntax error recovery when the query contains syntax errors. If the
parser encounters an error, it does not attempt to parse the rest of the code.
It all comes down to
libpg_query having a single error field per parse tree.
This makes it unsuitable for usage in code editors. When editing, most of the time the code has a syntax error, because the user is still typing the word, or is editing some more complex statement.
For example, given the following query:
SELECT
"gid",
"state"
FROM
"splitgraph/election-geodata:79724cbf5dcd2b260ac0d60e58135123d527ff4d2e1dc709f6da47fa8f4ee71f"."nation"
LIMIT 100;
When the user wants to select one more column in a SELECT statement:
SELECT
"gid",
,
-- look, a syntax error. There cannot be a trailing comma above
"state"
FROM
"splitgraph/election-geodata:79724cbf5dcd2b260ac0d60e58135123d527ff4d2e1dc709f6da47fa8f4ee71f"."nation"
LIMIT 100;
we should still be able to parse the query and know it references splitgraph/election-geodata despite the query having a syntax error.
This makes syntax error recovery a must-have for our parser.
sql-parser from sql-language-server
sql-parser is a JavaScript parser implemented using Peggy (a JavaScript parser generator). It is part of the sql-language-server.
Lack of syntax error recovery disqualifies this library. It also did not support
using schemas in table names (e.g. "splitgraph/election-geodata"."nation" was
considered a syntax error, but "splitgraph/election-geodata" was not).
tree-sitter
tree-sitter is a parser generator.
The generated parsers include syntax error recovery. When there is a syntax
error, only a few AST nodes get marked as ERROR, but the rest of the code is
parsed like normal. It also supports incremental parsing. This means doing a
re-parse of the code after editing it is more efficient than parsing from
scratch if only we provide tree-sitter the previous AST and the description of
the modified range of code.
Both of these qualities make tree-sitter well-suited for code editors. In fact, it is used in neovim, Atom, Emacs, and Helix, to name a few. Tree-sitter also powers basic IDE operations in web versions of VSCode (like https://vscode.dev/) thanks to the vscode-anycode extension. It also powers parsing of bash in the bash-language-server.
See Introduction to tree-sitter for a more detailed description of what tree-sitter can do.
Tree-sitter has bindings in many languages. The ones relevant to us are:
- web-tree-sitter for WASM,
- node-tree-sitter for Node.js.
As for the grammar, tree-sitter-sql is a well-maintained SQL grammar used in Neovim. In our testing, it successfully parsed the pgSQL we threw at it, and the parts it stumbled on were fixed in just a handful of days.
All of the above led us to decide tree-sitter is the right choice for parsing pgSQL in the Console.
Extracting referenced tables from the query
Tree-sitter parses the query into an AST. The corpus tests of the grammar show the stringified AST node types. Now the challenge becomes extracting the referenced tables from that AST.
Neovim's :InspectTree command is extremely useful at understanding the AST
while interactively editing code.
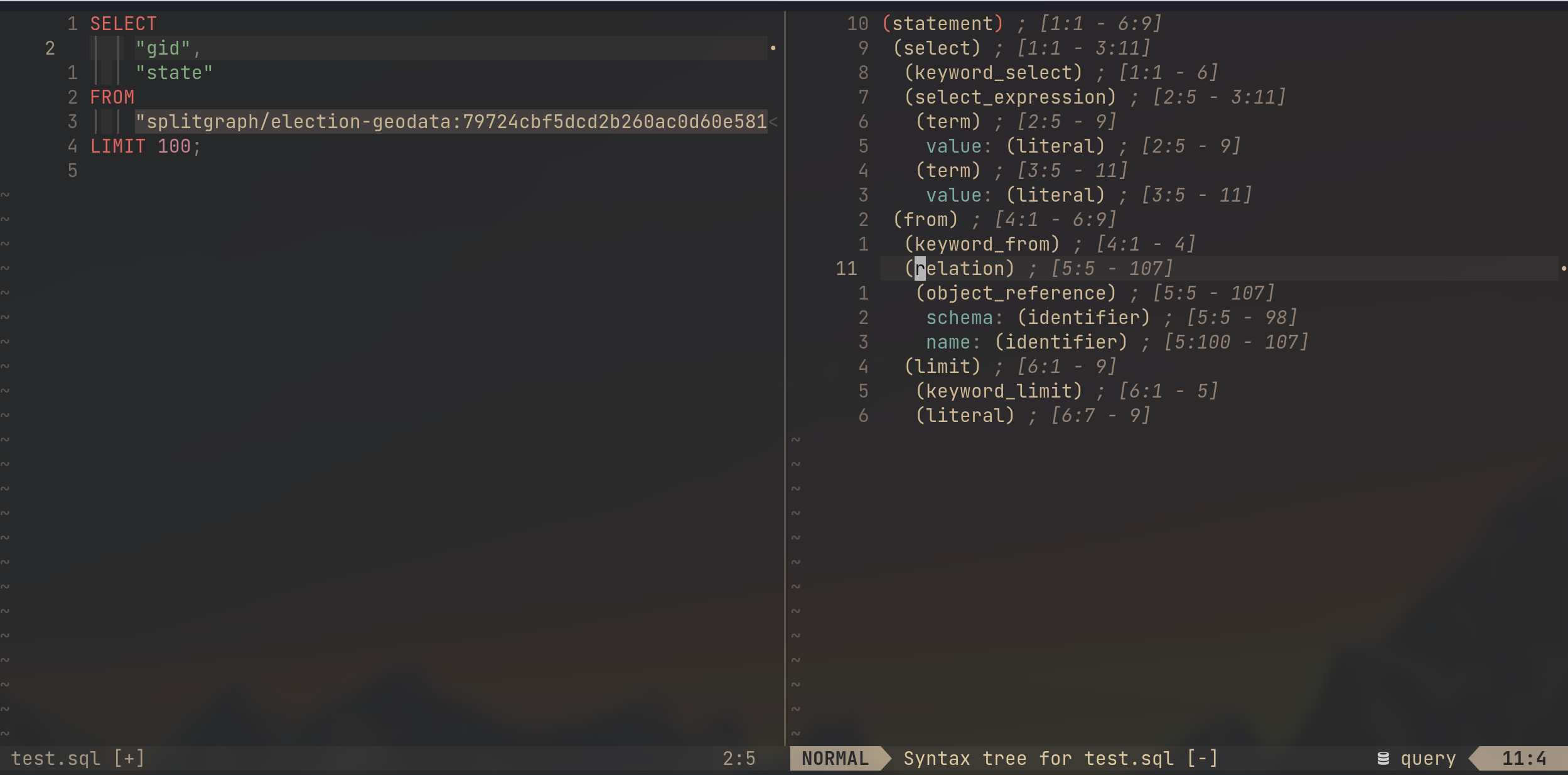
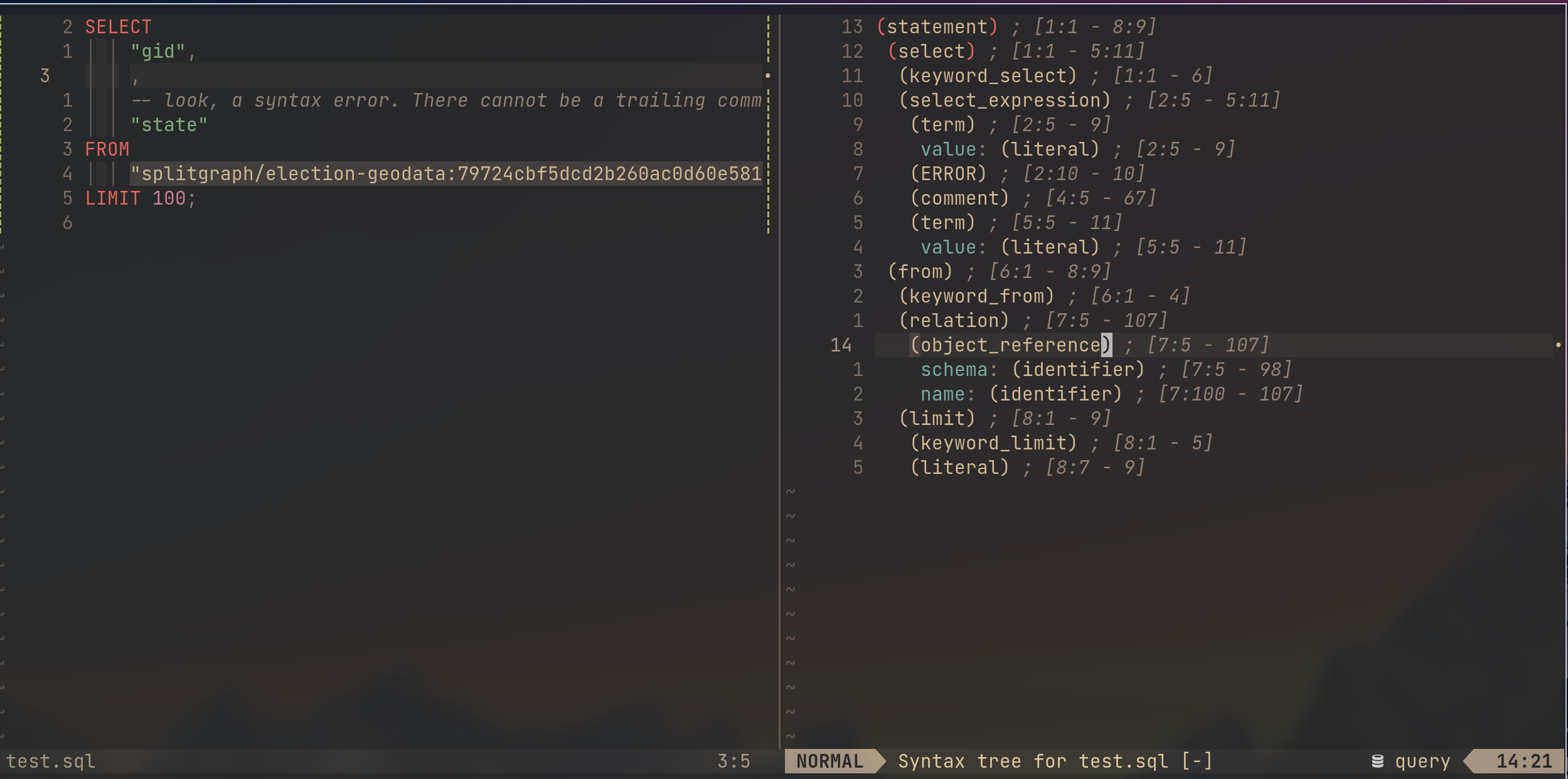
Here we can also see the AST parsed from a query that has a syntax error.
Tree-sitter also supports declaratively querying the AST using queries written as S-expressions. It takes away the burden of walking the AST and looking for subtrees that match a certain shape. We ended up with the following query to capture the referenced tables:
(
relation (
(
object_reference
schema: (identifier)
name: (identifier)
) @reference
)
)
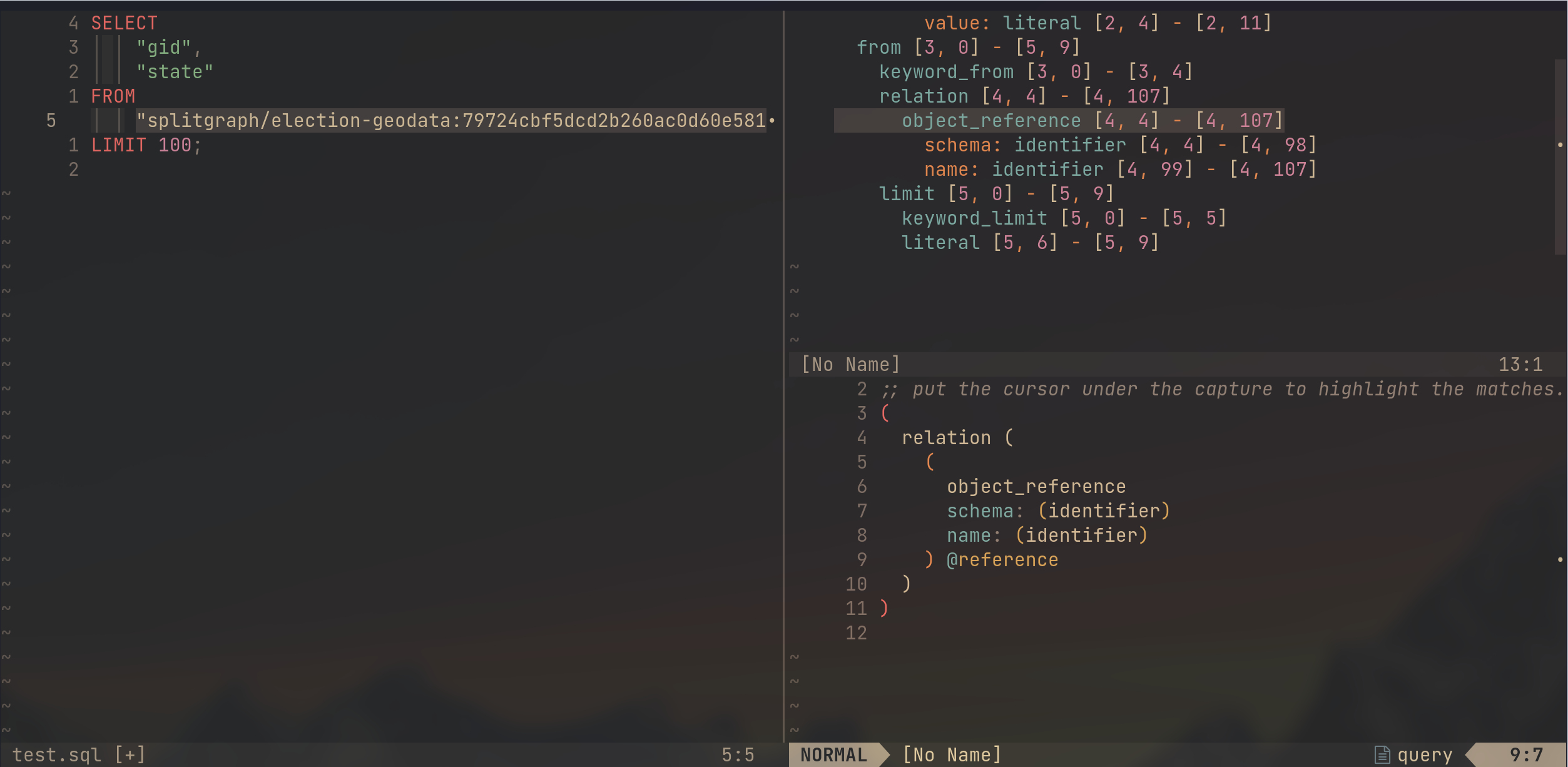
This query ended up capturing the table reference we care about.
Extracting parts of a table reference
Tree-sitter gives us back the table reference as a string like
"splitgraph/election-geodata:79724cbf5dcd2b260ac0d60e58135123d527ff4d2e1dc709f6da47fa8f4ee71f"."nation".
Now it is our job to extract the namespace, repository name, image tag, and the
table name from this reference.
This felt like a good job for a regular expression. We ended up with the following one and wrote a bunch of test cases to make sure it also tolerates errors (e.g. a missing table name at the end when the user is still typing it):
const tableReferenceRegExp = /^"((?<namespace>[^/]+)?)(\/((?<repositoryName>[^":]+)?)(:((?<imageTag>[^"]+)?))?"?(\."?((?<tableName>[^"]+)?)"?)?)?$/;
It uses named capturing groups to make extracting the reference parts easier.
Result
Tying these pieces together, the Splitgraph Console query editor now supports displaying referenced tables in the sidebar as a tree. It updates nearly instantly. We added a debounce to avoid updating the UI so often.
We found that the tree-sitter parsing process usually takes less than 1ms on a laptop. Using 6x CPU throttling in Chrome still leads to a usable UI.
Check it out
Boost your SQL writing experience with live query introspection.
Bonus: supabase/postgres_lsp discussion
As we were working on integrating tree-sitter in the Splitgraph Console, Supabase was working on the postgres_lsp, a language server for PostgreSQL.
Creating a language server involves much more work than just the parser. It can provide diagnostics, autocomplete, semantic highlighting, code actions, "Go to definition", and many other features.
The parser is still at the core of a language server. Omitting error recovery from the parser used in a language server can lead to frustrating experience for the users.
For example, with semantic highlighting, the user will have a jarring experience if the query stops being highlighted each other keystroke due to intermittent parsing errors.
Autocomplete also is problematic to get working when suggestions are only available when the query is valid. Most of the time the user will request suggestions for a half-written query, which, most likely, is not a valid query yet. If the server does not implement syntax error recovery during parsing, it will keep yielding empty or wrong suggestions.
TypeScript server (tsserver) which is used in the TypeScript Language Server,
has advanced syntax error recovery which offers stellar TypeScript authoring
experience. Syntax error recovery is heavily integrated into the parser, for
example:
- nodes are annotated when surrounding nodes have errors,
- missing nodes are created when there are errors in the AST,
- parsing functions are aware whether the parser is in "error recovery" mode and adjust their behavior.
At the time of writing this article (2023-08-09), postgres_lsp employs some measures to handle syntax errors returned by pg_query.rs (source). Their LSP is still at a very early stage and only supports semantic highlighting (and keeps crashing quite often), which makes it hard to assess. We are very interested to see if using a parser with no syntax error recovery as a base will be a viable solution.
That said, we are extremely excited that there is development in this space.
Splitgraph
Made with


on four continents.